复合类型
复合类型
结构体 - 新
方法
基本使用 - 定义、创建、访问
// 定义结构体
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
// 创建实例
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
}
// 访问
user1.email = String::from("anotheremail@example.com");简化 - key value 同名省略
当 key: value 中两侧的key名和变量名相同时,可以省略 key:。这点和js一样
简化 - 结构体更新语法
类似于 typescript 的 ... (剩余参数、扩展运算符)
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
// 简化为
let user2 = User {
email: String::from("another@example.com"),
..user1
};.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
注
结构体更新语法跟赋值语句 = 非常相像,因此在上面代码中,user1 的部分字段所有权被转移到 user2 中:username 字段发生了所有权转移,作为结果,user1 无法再被使用。
聪明的读者肯定要发问了:明明有三个字段进行了自动赋值,为何只有 username 发生了所有权转移?
仔细回想一下所有权那一节的内容,我们提到了 Copy 特征:实现了 Copy 特征的类型无需所有权转移,可以直接在赋值时进行
数据拷贝,其中 bool 和 u64 类型就实现了 Copy 特征,因此 active 和 sign_in_count 字段在赋值给 user2 时,仅仅发生了拷贝,而不是所有权转移。
值得注意的是:username 所有权被转移给了 user2,导致了 user1 无法再被使用,但是并不代表 user1 内部的其它字段不能被继续使用,例如:
# #[derive(Debug)]
# struct User {
# active: bool,
# username: String,
# email: String,
# sign_in_count: u64,
# }
# fn main() {
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);
# }原理、内存排列
先来看以下代码:
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
fn main() {
let f1 = File {
name: String::from("f1.txt"),
data: Vec::new(),
};
let f1_name = &f1.name;
let f1_length = &f1.data.len();
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}上面定义的 File 结构体在内存中的排列如下图所示:
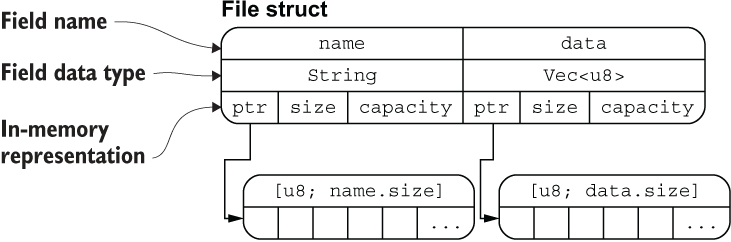
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
特殊结构体
元组结构体(Tuple Struct)
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为:x, y, z。
笔者
但是话说我不太理解应用场景
和元组的功能不是重合了吗
单元结构体(Unit-like Struct)
还记得之前讲过的基本没啥用的单元类型吧?单元结构体就跟它很像,没有任何字段和属性,但是好在,它还挺有用。
应用场景: 如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 单元结构体:
struct AlwaysEqual; // 单元结构体
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}看起来有点类似Cpp中继承一个无实现的抽象基类
所有权问题
在之前的 User 结构体的定义中,有一处细节:我们使用了自身拥有所有权的 String 类型而不是基于引用的 &str 字符串切片类型。这是一个有意而为之的选择:因为我们想要这个结构体拥有它所有的数据,而不是从其它地方借用数据。
你也可以让 User 结构体从其它对象借用数据,不过这么做,就需要引入生命周期(lifetimes)这个新概念(也是一个复杂的概念),简而言之,生命周期能确保结构体的作用范围要比它所借用的数据的作用范围要小。
总之,如果你想在结构体中使用一个引用,就必须加上生命周期,否则就会报错:
struct User {
username: &str,
email: &str,
sign_in_count: u64,
active: bool,
}
fn main() {
let user1 = User {
email: "someone@example.com",
username: "someusername123",
active: true,
sign_in_count: 1,
};
}编译器会抱怨它需要生命周期标识符:
error[E0106]: missing lifetime specifier
--> src/main.rs:2:15
|
2 | username: &str,
| ^ expected named lifetime parameter // 需要一个生命周期
|
help: consider introducing a named lifetime parameter // 考虑像下面的代码这样引入一个生命周期
|
1 ~ struct User<'a> {
2 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:3:12
|
3 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | username: &str,
3 ~ email: &'a str,
|未来在生命周期中会讲到如何修复这个问题以便在结构体中存储引用,不过在那之前,我们会避免在结构体中使用引用类型。
打印 (#[derive(Debug)])
display/debug 特征问题
以前学习的基本类型,都默认实现了Display特征。默认结构体没有该特征,直接打印会报错:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
// 提示我们结构体 `Rectangle` 没有实现 `Display` 特征
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
// 提示我们使用 `{:?}` 来试试
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
// 让我们实现 `Debug` 特征
// 或者加 `#[derive(Debug)]`为什么不默认实现 Display 特征呢?
原因在于结构体较为复杂,例如考虑以下问题:你想要逗号对字段进行分割吗?需要括号吗?加在什么地方?所有的字段都应该显示?类似的还有很多,由于这种复杂性,Rust 不希望猜测我们想要的是什么,而是把选择权交给我们自己来实现:如果要用 {} 的方式打印结构体,那就自己实现 Display 特征。
那么实现有两种方法:
解决方法1 - 手动实现
略
解决方法2 - derive 派生实现
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
}
// 打印
rect1 is Rectangle { width: 30, height: 50 }
// 可以用 {:#?} 来替代 {:?},则打印如下
rect1 is Rectangle {
width: 30,
height: 50,
}解决方法3 - dbg! 宏
还有一个简单的输出 debug 信息的方法,那就是使用 dbg! 宏,它会拿走表达式的所有权,然后打印出相应的文件名、行号等 debug 信息,当然还有我们需要的表达式的求值结果。除此之外,它最终还会把表达式值的所有权返回!
dbg!输出到标准错误输出stderr,而println!输出到标准输出stdout。
下面的例子中清晰的展示了 dbg! 如何在打印出信息的同时,还把表达式的值赋给了 width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}最终的 debug 输出如下:
$ cargo run
[src/main.rs:10] 30 * scale = 60
[src/main.rs:14] &rect1 = Rectangle {
width: 60,
height: 50,
}可以看到,我们想要的 debug 信息几乎都有了:代码所在的文件名、行号、表达式以及表达式的值,简直完美!
枚举 - 新
Option 枚举用于处理空值
设计
Tony Hoare, null 的发明者,曾经说过一段非常有名的话:
我称之为我十亿美元的错误。当时,我在使用一个面向对象语言设计第一个综合性的面向引用的类型系统。我的目标是通过编译器的自动检查来保证所有引用的使用都应该是绝对安全的。不过在设计过程中,我未能抵抗住诱惑,引入了空引用的概念,因为它非常容易实现。就是因为这个决策,引发了无数错误、漏洞和系统崩溃,在之后的四十多年中造成了数十亿美元的苦痛和伤害。
与其他语言不同,Rust没有 null
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出 null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。
尽管如此,空值的表达依然非常有意义,因为空值表示当前时刻变量的值是缺失的。有鉴于此,Rust 吸取了众多教训,决定抛弃 null,而改为使用 Option 枚举变量来表述这种结果。
为什么 option比空值好?(Option的三大特性)
- 明确性
明确表示可能不存在的值
在可能出现空值的情况下,我们可以处理 之,而不会遗忘! - 强制性
强制进行空值检查,不然会报错,极大避免了空值访问的错误 - 可读性
更好的语义和代码可读性
不过话说ts的语法也挺好啊,
typeX|null|undefined这样。或者加个?Option枚举感觉和这个挺像。多了个Some……感觉没那么简洁
原型、源码
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
enum Option<T> {
Some(T),
None,
}其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。
- 无需手动引入:
Option<T>枚举是如此有用以至于它被包含在了prelude(prelude 属于 Rust 标准库,Rust 会将最常用的类型、函数等提前引入其中,省得我们再手动引入)之中,你不需要将其显式引入作用域。 - 无需前缀:
另外,它的成员Some和None也是如此,无需使用Option::前缀就可直接使用Some和None。总之,不能因为Some(T)和None中没有Option::的身影,就否认它们是Option下的卧龙凤雏。
使用
再来看以下代码:
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;那么,Option<T> 为什么就比空值要好呢?
简而言之,因为 Option<T> 和 T(这里 T 可以是任何类型)是不同的类型,例如,这段代码不能编译,因为它尝试将 Option<i8>(Option<T>) 与 i8(T) 相加:
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y; // 该代码会报错。应该将 Option<i8> 转 i8,才能进行运算
// 报错如下
error[E0277]: the trait bound `i8: std::ops::Add<std::option::Option<i8>>` is
not satisfied
-->
|
5 | let sum = x + y;
| ^ no implementation for `i8 + std::option::Option<i8>`
|配合 match (模式匹配)
总的来说,为了使用 Option<T> 值,需要编写处理每个成员的代码。你想要一些代码只当拥有 Some(T) 值时运行,允许这些代码使用其中的 T。也希望一些代码在值为 None 时运行,这些代码并没有一个可用的 T 值。match 表达式就是这么一个处理枚举的控制流结构:它会根据枚举的成员运行不同的代码,这些代码可以使用匹配到的值中的数据。
这里先简单看一下 match 的大致模样,在模式匹配中,我们会详细讲解:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five); // 6
let none = plus_one(None); // noneplus_one 通过 match 来处理不同 Option 的情况。
结构体 (Struct)
三种类型
结构体( struct )可以由各种不同类型组成。使用 struct 关键字来创建。struct 是 structure 的缩写。
结构体可以作为另一个结构体的字段。结构体是可以嵌套的。
有三种类型:
// 1. 经典的 C 语言风格结构体(C struct)
struct 结构体名称 {
...
}
// 2. 单元结构体(unit struct),不带字段,在泛型中很有用。
struct Unit;
// 3. 元组结构体(tuple struct),事实上就是具名元组而已。
struct Pair(String, i32);下面主要以C风格结构体为例
(1) C风格结构体
定义
struct 结构体名称 {
字段1: 数据类型,
字段2: 数据类型,
...
}创建、初始化
其实就是对 结构体中的各个元素进行赋值
let 实例名称 = 结构体名称 {
field1: value1,
field2: value2
...
};示例
#[derive(Debug)]
struct Study {
name: String,
target: String,
spend: i32,
}
fn main() {
let s = Study {
name: String::from("从0到Go语言微服务架构师"),
target: String::from("全面掌握Go语言微服务落地,代码级一次性解决微服务和分布式系统。"),
spend: 3,
};
println!("{:?}", s);
}
// 输出
Study { name: "从0到Go语言微服务架构师", target: "全面掌握Go语言微服务落地,代码级一次性解决微服务和分布式系统。", spend: 3 }访问实例属性
实例名称.属性示例
println!("{}", s.name); // 输出 从0到Go语言微服务架构师修改结构体实例
结构体实例默认是不可修改的,如果想修改结构体实例,声明时使用mut关键字。
let mut s2 = Study {
name: String::from("从0到Go语言微服务架构师"),
target: String::from("全面掌握Go语言微服务落地,代码级一次性解决微服务和分布式系统。"),
spend: 3,
};
s2.spend = 7; // 修改
println!("{:?}", s2);
// 输出
Study { name: "从0到Go语言微服务架构师", target: "全面掌握Go语言微服务落地,代码级一次性解决微服务和分布式系统。", spend: 7 }结构体做参数
fn show(s: Study) {
println!(
"name is :{} target is {} spend is{}", s.name, s.target, s.spend
);
}结构体作为返回值
fn get_instance(name: String, target: String, spend: i32) -> Study {
return Study {
name,
target,
spend,
};
}
let s3 = get_instance(
String::from("Go语言极简一本通"),
String::from("学习Go语言语法,并且完成一个单体服务"),
5,
);
println!("{:?}", s3);
// 输出:
Study { name: "Go语言极简一本通", target: "学习Go语言语法,并且完成一个单体服务", spend: 5 }结构体方法
普通方法
方法(method)是依附于对象的函数。这些方法通过关键字 self 来访问对象中的数据和其他。方法在 impl 代码块中定义。
与函数的区别
- 函数:可以直接调用,同一个程序不能出现 2 个相同的函数签名的函数,应为函数不归属任何 owner。
- 方法:归属某一个 owner,不同的 owner 可以有相同的方法签名。
impl 结构体 { // "impl" 是 "implement" 的缩写。意思是 “实现”的意思。
fn 方法名(&self, 参数列表) 返回值 { // "self" 是 "自己" 的意思。
// &self 表示当前结构体的实例。&self 也是结构体普通方法固定的第一个参数,其他参数可选。
// 方法体
}
}结构体方法的作用域仅限于结构体内部。
impl Study {
fn get_spend(&self) -> i32 {
return self.spend;
}
}
println!("spend {}", s3.get_spend());
// 输出 spend 5静态方法
// 定义
fn 方法名(参数: 数据类型, ...) -> 返回值类型 { // 与普通方法的区别:没有 &self 作为第一个参数
// 方法体
}
// 调用
结构体名称::方法名(参数列表)示例
impl Study {
...
fn get_instance_another(name: String, target: String, spend: i32) -> Study {
return Study {
name,
target,
spend,
};
}
}
let s4 = Study::get_instance_another(
String::from("Go语言极简一本通"),
String::from("学习Go语言语法,并且完成一个单体服务"),
5,
);(2) 单元结构体 (unit type)
unit type 是一个类型,有且仅有一个值:
(),单元类型()类似 c/c++/java 语言中的 void
- 当一个函数并不需要返回值的时候,其他语言返回void
- rust 则返回()
但语法层面上,void 仅仅只是一个类型,该类型没有任何值;而单元类型()既是一个类型,同时又是该类型的值。
(3) 元祖结构体
实例化
let pair = (String::from("从0到Go语言微服务架构师"), 1);访问
访问元组结构体的字段
println!("pair 包含 {:?} and {:?}", pair.0, pair.1);
// 输出:
pair 包含"从0到Go语言微服务架构师" and 1解构
解构一个元组结构体
let (study, spend) = pair;
println!("pair 包含 {:?} and {:?}", study, spend);
// 输出:内容同上
pair 包含"从0到Go语言微服务架构师" and 1枚举 (Enum)
枚举 enum 关键字允许创建一个从数个不同取值中选其一的枚举类型(enumeration)。任何一个在 struct 中合法的取值在 enum 中也合法。
在日常生活中很常见。比如:1 年有 12 个月,1 周有 7 天。
枚举的定义
enum 枚举名称{
variant1,
variant2,
...
}使用枚举
枚举名称::variant示例
#[derive(Debug)] // #[derive(Debug)] 注解的作用,就是让 派生自Debug。
enum RoadMap {
Go语言极简一本通,
Go语言微服务架构核心22讲,
从0到Go语言微服务架构师,
}
fn main() {
let level = RoadMap::从0到Go语言微服务架构师;
println!("level---{:?}", level);
}Option 枚举
enum Option<T> {
Some(T), // 用于返回一个值
None // 用于返回 null,用None来代替。
}Option 枚举经常用在函数中的返回值,它可以表示有返回值,也可以用于表示没有返回值。如果有返回值。
可以使用返回 Some(data),如果函数没有返回值,可以返回 None。
fn getDiscount(price: i32) -> Option<bool> {
if price > 100 {
Some(true)
} else {
None
}
}
let p = 666; // 输出 Some(true)
// let p=6; // 输出 None
let result = getDiscount(p);
println!("{:?}", result)match 语句
判断一个枚举变量的值,唯一操作符就是 match。
fn print_road_map(r:RoadMap){
match r {
RoadMap::Go语言极简一本通=>{
println!("Go语言极简一本通");
},
RoadMap::Go语言微服务架构核心22讲=>{
println!("Go语言微服务架构核心22讲");
},
RoadMap::从0到Go语言微服务架构师=>{
println!("从0到Go语言微服务架构师");
}
}
}
print_road_map(RoadMap::Go语言极简一本通); // 输出 Go语言极简一本通
print_road_map(RoadMap::Go语言微服务架构核心22讲); // 输出 Go语言微服务架构核心22讲
print_road_map(RoadMap::从0到Go语言微服务架构师); // 输出 从0到Go语言微服务架构师带数据类型的枚举
(不知道能怎么用)
enum 枚举名称 {
variant1(数据类型1),
variant2(数据类型2),
...
}示例
#[derive(Debug)]
enum StudyRoadMap {
Name(String),
}
let level3 = StudyRoadMap::Name(String::from("从0到Go语言微服务架构师"));
match level3 {
StudyRoadMap::Name(val) => {
println!("{:?}", val);
}
}
//输出 "从0到Go语言微服务架构师"集合 (Collections) - 未
Rust 语言标准库提供了通用的数据结构的实现。包括:
- 向量 (Vector)
- 哈希表( HashMap )
- 哈希集合( HashSet )
向量 (Vector)
Rust 在标准库中定义了结构体 Vec 用于表示一个向量。向量和数组很相似,只是数组长度是编译时就确定了,定义后就不能改变了,那要么改数组,让他支持可变长度,显然 Rust 没有这么做,它用向量这个数据结构,也是在内存中开辟一段连续的内存空间来存储元素。
特点:
- 向量中的元素都是相同类型元素的集合。
- 长度可变,运行时可以增加和减少。
- 使用索引查找元素。(索引从 0 开始)
- 添加元素时,添加到向量尾部。
- 向量的内存在堆上,长度可动态变化。
创建向量
new() 静态方法用于创建一个结构体 Vec 的实例。let mut 向量的变量名称 = Vec::new();
vec!() 宏来简化向量的创建。let 向量的变量名称 = vec![val1,val2,...]
向量的使用方法
| 方法 | 说明 |
|---|---|
| new() | 创建一个空的向量的实例 |
| push() | 将某个值 T 添加到向量的末尾 |
| remove() | 删除并返回指定的下标元素 |
| contains() | 判断向量是否包含某个值 |
| len() | 返回向量中的元素个数 |
let mut v = Vec::new();//调用 Vec 结构的 new() 静态方法来创建向量。
v.push("Go语言极简一本通"); //通过push方法添加元素数据。并且追加到向量尾部。
v.push("Go语言微服务核心架构22讲");
v.push("从0到Go语言微服务架构师");
println!("{:?}",v);
println!("len :{}",v.len()); // 通过len方法获取向量中的元素个数。
let mut v2 = vec!["Go语言极简一本通","Go语言微服务核心架构22讲","从0到Go语言微服务架构师"];
// 通过vect!宏创建向量时,向量的数据类型由第一个元素自动推断出来。
println!("{:?}",v2);
let x=v2.remove(0);
// remove()方法移除并返回向量中指定的下标索引处的元素,将其后面的所有元素移到向左移动一位。
println!("{}",x); //输出 Go语言极简一本通
println!("{:?}",v2);//输出 ["Go语言微服务核心架构22讲", "从0到Go语言微服务架构师"]
//contains() 用于判断向量是否包含某个值。如果值在向量中存在则返回 true,否则返回 false。
if v.contains(&"从0到Go语言微服务架构师"){
println!("找到了")
}
//访问向量中的某个元素,使用索引
let y = v[0];
println!("{}",y); //输出 Go语言极简一本通
//遍历向量
for item in v {
println!("充电项目: {}", item);
}
//输出
充电项目: Go语言极简一本通
充电项目: Go语言微服务核心架构22讲
充电项目: 从0到Go语言微服务架构师哈希表 (HashMap)
HashMap 就是键值对集合。键是不能重复的,值是可以重复的。
使用 HashMap 结构体之前需要显式导入 std::collections 模块。
创建 HashMap
使用 new()方法来创建。
let mut 变量名称 = HashMap::new();
这个哈希表只有当我们添加了元素之后才能正常使用。因为现在还没指定的数据类型。
| 方法 | 说明 |
|---|---|
| insert() | 插入/更新一个键值对到哈希表中,如果数据已经存在则返回旧值,如果不存在则返回 None |
| len() | 返回哈希表中键值对的个数 |
| get() | 根据键从哈希表中获取相应的值 |
| iter() | 返回哈希表键值对的无序迭代器,迭代器元素类型为 (&’a K, &’a V) |
| contains_key | 如果哈希表中存在指定的键则返回 true 否则返回 false |
| remove() | 从哈希表中删除并返回指定的键值对 |
use std::collections::HashMap;
let mut process = HashMap::new();
process.insert("Go语言极简一本通", 1);
process.insert("Go语言微服务核心架构22讲", 2);
process.insert("从0到Go语言微服务架构师", 3);
println!("{:?}", process);
//输出 {"Go语言极简一本通": 1, "Go语言微服务核心架构22讲": 2, "从0到Go语言微服务架构师": 3}
println!("len {}",menu.len());
//输出 3
// get() 方法用于根据键从哈希表中获取相应的值。
match process.get(&"从0到Go语言微服务架构师"){
Some(v)=>{
println!("HashMap v:{}", v);
}
None=>{
println!("找不到");
}
}
//输出 HashMap v:3
//迭代哈希表 iter()
for (k, v) in process.iter() {
println!("k: {} v: {}", k, v);
}
//输出
k: Go语言微服务核心架构22讲 v: 2
k: 从0到Go语言微服务架构师 v: 3
k: Go语言极简一本通 v: 1
// contains_key() 方法用于判断哈希表中是否包含指定的 键值对。如果包含指定的键,那么会返回相应的值的引用,否则返回 None。
if process.contains_key(&"Go语言极简一本通") {
println!("找到了");
}
//输出 找到了
// remove() 用于从哈希表中删除指定的键值对。如果键值对存在则返回删除的键值对,返回的数据格式为 (&'a K, &'a V)。如果键值对不存在则返回 None
let x=process.remove(&"Go语言极简一本通");
println!("{:?}",x);
println!("{:?}",process);
//输出
Some(1)
{"Go语言微服务核心架构22讲": 2, "从0到Go语言微服务架构师": 3}哈希集合 (HashSet)
Hashset 是相同数据类型的集合,它是没有重复值的。如果集合中已经存在相同的值,则会插入失败。
创建 Hashset
let mut 变量名称 = HashSet::new();
常用方法如下
方法 描述
insert() 插入一个值到集合中 如果集合已经存在值则插入失败
len() 返回集合中的元素个数
get() 根据指定的值获取集合中相应值的一个引用
iter() 返回集合中所有元素组成的无序迭代器 迭代器元素的类型为 &'a T
contains_key 判断集合是否包含指定的值
remove() 从结合中删除指定的值
insert() 用于插入一个值到集合中。
let mut studySet = HashSet::new();
studySet.insert("Go语言极简一本通");
studySet.insert("Go语言微服务核心架构22讲");
studySet.insert("从0到Go语言微服务架构师");
println!("{:?}", studySet);
//输出 {"从0到Go语言微服务架构师", "Go语言微服务核心架构22讲", "Go语言极简一本通"}
studySet.insert("从0到Go语言微服务架构师");
println!("{:?}", studySet);
//输出 {"从0到Go语言微服务架构师", "Go语言微服务核心架构22讲", "Go语言极简一本通"}len() 方法集合中元素的个数。
println!("len:{}",studySet.len());//输出 len:3iter() 方法用于返回集合中所有元素组成的无序迭代器。
for item in studySet.iter(){
println!("hashSet-充电项目: {}", item);
}
//输出
hashSet-充电项目: Go语言极简一本通
hashSet-充电项目: Go语言微服务核心架构22讲
hashSet-充电项目: 从0到Go语言微服务架构师get() 方法用于获取集合中指定值的一个引用。
match studySet.get("从0到Go语言微服务架构师") {
None => {
println!("没找到");
}
Some(data) => {
println!("studySet中找到:{}",data);
}
}
//输出 studySet中找到:从0到Go语言微服务架构师contains() 方法用于判断集合是否包含指定的值。
if studySet.contains("Go语言微服务核心架构22讲"){
println!("包含 Go语言微服务核心架构22讲")
}
//输出 包含 Go语言微服务核心架构22讲remove() 方法用于从集合中删除指定的值。如果该值在集合中,则返回 true,如果不存在则返回 false。
studySet.remove("Go语言极简一本通");
println!("{:?}",studySet);//输出 {"Go语言微服务核心架构22讲", "从0到Go语言微服务架构师"}
studySet.remove("golang");
println!("{:?}",studySet);//输出 {"Go语言微服务核心架构22讲", "从0到Go语言微服务架构师"}