字符编码详解
字符编码详解
- 相关参考
目录
[toc]
字符编码的语言兼容
字符编码简概
各种编码介绍
各国编码
仅列举常见的,不全,详见 【wikipedia】字符编码
| 各国编码 | 地区 | 存储大小 | 补充 |
|---|---|---|---|
| ASCII | 美国 | 1字节中的7位 | 128,开头为0 |
| ISO-8859-1 | 欧洲 | 1字节中的8位 | ASCII基础上扩充另一半(扩展ASCII编码表) |
| GB2312>GBK>GB18030 | 中国 | 3字节 | ASCII基础上加2个字节映射新增字符,新的GB兼容旧的 |
| BIG5 | 台湾 | 略 | 也叫大五码 |
| JIS | 日本 | 略 | 略 |
| ANSI | 全世界 | 会变 | 范畴,根据操作系统语言而改变,简体中文>GB2312,繁体中文>Big5,日文>JIS |
| Unicode | 全世界 | 会变 | 存储时要先查表,再转换(其他编码没第二步)转换规则:Utf-8,Utf-16,Utf-32 |
Unicode
详见Unocde一章
字符编码类型
ANSI 系统编码
除了ANSI,有时编程上的形式为local8bit,而国内的windows默认使用(GBK/GB2312/GB18030)
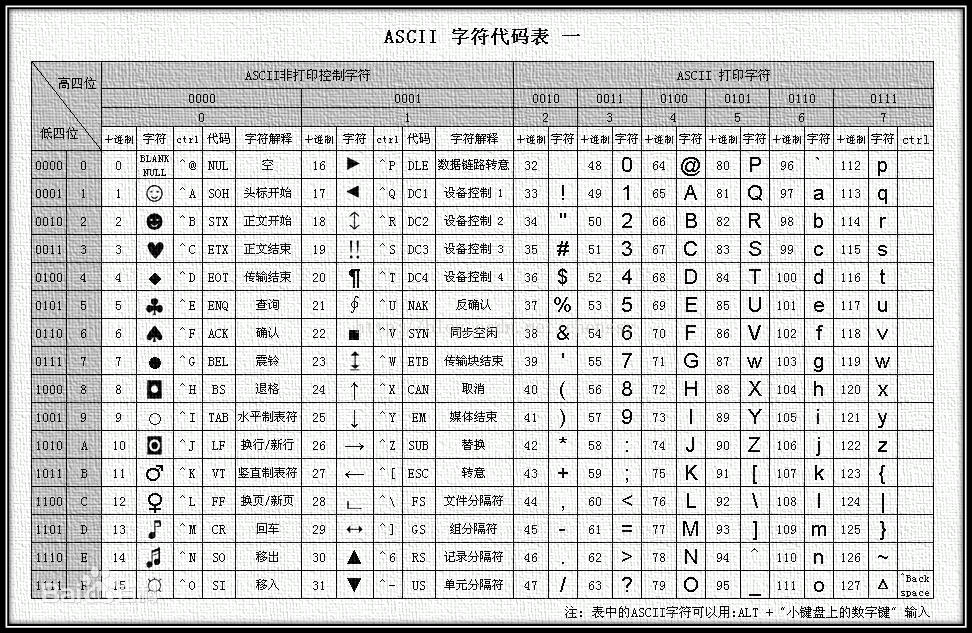
ASCII
ASCII字符代码表(都位于[signed] char的正侧(高左低右,和十进制一样))
Unicode
历史渊缘
- Unicode出现之前
- 在Unicode出现之前,已经有许多种不同的标准:美国的ASCII、西欧语言中的ISO 8859-1、俄罗斯的KOI-8、中国的GB 18030和BIG-5等。
- 这样就产生了下面两个问题:
- 一个是对于任意给定的代码值,在不同的编码方案下有可能对应不同的字母;
- 二是采用大字符集的语言其编码长度有可能不同。例如,有些常用的字符采用单字节编码,而另一些字符则需要两个或更多个字节。
- 1991年:Unicode 1.0
- 在20世纪80年代开始启动设计工作时,人们认为两个字节的代码宽度足以对世界上各种语言的所有字符进行编码,并有足够的空间留给未来的扩展。
- 在1991年发布了Unicode 1.0,当时仅占用65536个代码值中不到一半的部分。
- 在设计Java时也决定了采用16位的Unicode字符集
- 经过一段时间,不可避免的事情发生了。Unicode字符超过了65536个,其主要原因是增加了大量的汉语、日语和韩语中的表意文字。
- UTF-16
- 用一些专用术语解释一下
码点(code point)是指与一个编码表中的某个字符对应的代码值。在Unicode标准中,码点采用十六进制书写,并加上前缀U+,
例如U+0041就是拉丁字母A的码点。- Unicode的码点可以分成17个
代码级别(code plane)。
第一个代码级别称为基本的多语言级别(basic multilingual plane),
码点从U+0000到U+FFFF(恰好为两字节的存储空间),其中包括经典的Unicode代码;
其余的16个级别码点从U+10000到U+10FFFF,其中包括一些辅助字符(supplementary character)。 - UTF-16编码采用不同长度的编码表示所有Unicode码点。在基本的多语言级别中,每个字符用16位表示,通常被称为
代码单元(code unit); - 而辅助字符采用一对连续的代码单元进行编码。这样构成的编码值落入基本的多语言级别中空闲的2048字节内,通常被称为替代区域(surrogate area)[U+D800~U+DBFF用于第一个代码单元,U+DC00~U+DFFF用于第二个代码单元]。这样设计十分巧妙,我们可以从中迅速地知道一个代码单元是一个字符的编码,还是一个辅助字符的第一或第二部分。
Unicode以及其变形
| Unicode编码 | 存储大小 | 补充 |
|---|---|---|
| UTF-8 UTF-8-BOM | 变长,1字节/2字节/3字节/4字节 (4种) 16进制表现:1/2组\uXXXX表示 0800-ffff是3bytes | 字符的长度随机而不占满,特点:节省存储空间 开头:0(ascii),10,110,1110,11110分别代表不同意义和字节长度 |
| UTF-16 | 变长,2字节/4字节 (2种) 16进制表现:1/2组\uXXXX表示 | 介于UTF-8和UTF-32之间 |
| UTF-32 | 定长,4字节 (1种) 16进制表现:2组\uXXXX表示 | 查表后不转换直接存储,特点:拿空间换时间 |
| UCS-2 Big Endian UCS-2 Little Endian | 略 | 对每一个Unicode码位使用2字节字集 UCS-2可看成UTF-16子集,不支持UTF-16中超过2字节的字集 |
| UCS-4 | 略 | UTF-32 原是 UCS-4 的子集,但就现状而言, 除了 UTF-32 标准包含额外的Unicode 意涵,UCS-4和UTF-32 大体是相同的 |
Unicode Or Utf8 补充
编程时代码编辑器一般是使用的utf-8编码
程序与语言或平台无关,为了代码共享用使用Unicode非常合理
网页浏览一般也用的utf-8。比起utf-32的内存换性能,网页文件的大小对性能的影响会更大
注意一下VS一般使用的是GBK,很坑
迁移问题
奇怪的Unicode开头 &#,&#x,\u
参考:https://blog.csdn.net/zhangge3663/article/details/84101832/
补充:8进制Unicode开头:\
Unicode字符分析
方法1
Unicode编码工具:https://tool.chinaz.com/tools/unicode.aspx
有时遇到一些奇怪的字符,但这种字符有时可以复制到支持Unicdoe编码的txt中的,那么可以复制到上面这个编码工具网站中查看其Unicode编码
方法2
还有一种方法是复制到txt中后,用非编码的方式打开(比如用16进制打开)
可以用NotePad++做到,打开NotePad++,菜单插件 > 插件管理 > 搜索HEX-Editor并安装(这个插件应该是本地的,安装后会重启一次)
> 菜单插件 > HEX-Editor > View in HEX(用16进制的方式查看)
Unicode与ASCII
存储大小:utf-8用
1字节存储ASCII码,即8个2进制/2个16进制Unicode开头:0
补充:Unicode有个范围和ASCII编码的关系是相关性的:凡是以0开头,即使用一个字节大小存储的都是ASCII编码
比如数字0,在Unicode中为30(16),转换为10进制位48(10),刚好对应ASCII编码
即Unicode编码和ASCII编码互转是比较方便的
0123456789 : ; < = > ? @
\u0030\u0031\u0032\u0033\u0034\u0035\u0036\u0037\u0038\u0039
\u003a\u003b\u003c\u003d\u003e\u003f\u0040
<>
(\u0026\u006c\u0074\u003b,\u0026\u0067\u0074\u003b)
A~Z
\u0041\u0042\u0043\u0044\u0045\u0046\u0047\u0048\u0049
\u004a\u004b\u004c\u004d\u004e\u004f
\u0050\u0051\u0052\u0053\u0054\u0055\u0056\u0057\u0058\u0059
\u005a
[ \ ] ^ _ `
\u005b\u005c\u005d\u005e\u005f\u0060
a~z
\u0061\u0062\u0063\u0064\u0065\u0066\u0067\u0068\u0069
\u006a\u006b\u006c\u006d\u006e\u006f
\u0070\u0071\u0072\u0073\u0074\u0075\u0076\u0077\u0078\u0079
\u007a
Utf-8与中文
中文存储大小:utf-8用
2/4字节存储汉字,即16个2进制/6个8进制/4个16进制(按2字节)Unicode开头:1110
奇怪的地方:但奇怪的是一般表示为9个8进制
Qt编码实例
中文: 你好世界 ———————————————————————————————————————————— Qt_编译结果:(MSVC和MinGW结果一样) \344\275\240 \345\245\275 \344\270\226 \347\225\214 Qt_编译结果转2进制:(这里的010有点诡异) 01110 0100 010 111101 010 100000 01110 0101 010 100101 010 111101 01110 0100 010 111000 010 010110 01110 0111 010 010101 010 001100 Qt_编译结果转16进制:(会发现很奇怪,对不上) 39 17aa0 39 54abd 39 17096 39 d2a8c ———————————————————————————————————————————— 16进制: \u4f60\u597d\u4e16\u754c 或你好世界 16进制转2进制:(记得补前面的0) 0100 111101 100000 0101 100101 111101 0100 111000 010110 0111 010101 001100 ———————————————————————————————————————————— (其实和GBK并没什么关系的,这里写出来是参考学习而已) GBK: e4baa0e5a5bde4b896e7958c GBK转utf-8: c4e3bac3cac0bde7 GBK转2进制: 1100010011100011 1011101011000011 1100101011000000 1011110111100111 ———————————————————————————————————————————— 用GBK解码utf8编码: 浣犲ソ涓栫晫 用utf8解码GBK编码: ģºÊÀ½(或者形式为实体长方格子,或者形式为问好) ———————————————————————————————————————————— (需要文件信息来提供文件编码) 纯文本UTF你好世界: e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c 你 好 世 界 浣? 濂? 涓? 鐣? 纯文本GBK你好世界: e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c
编码原理
编码与解码
编码与二进制/HEX
HEX分析可以用Notepad++
使用方法:打开NotePad++,菜单插件 > 插件管理 > 搜索HEX-Editor并安装(这个插件应该是本地的,安装后会重启一次)
> 菜单插件 > HEX-Editor > View in HEX(用16进制的方式查看)