Python爬虫
Python爬虫
目录
入门
合法性
- 道德规范(Robots协议)
- 查看robots.txt
- https://www.taobao.com/robots.txt
- 里面有注明 Allow 和 Disallow
- 引擎结果
- 由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述
- 自我约束
- 合理限定请求速度
- “三月爬虫”的故事
基本流程
获取网页
基础技术:request,urllib,selenium(模拟浏览器)
进阶技术:多进程多线程抓取、登陆抓取、突破IP封禁和服务器抓取
解析网页
- 基础技术:re正则表达式、BeautifulSoup、lxml
- 进阶技术:解决中文乱码
存储网页
- 基础技术:存入txt文件和存入csv文件
- 进阶技术:存入MySQL数据库和存入MongoDB数据库
环境准备
安装第三方包与开启服务器
安装Anaconda(Anaconda自带pip)
cd
pip install bs4 # BeautifulSoup第三个模块,能解析网页
pip install jupyter 或 conda install jupyter [notebook] # 安装jupyter
jupyter notebook # 启动jupyter服务器,默认是localhost:8888/tree主要流程
静态网站抓取(Requests标准模块)
# 第一个爬虫
import requests # 请求库
from bs4 import BeautifulSoup # bs库中的解析函数
link = 'http://www.santostang.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers = headers)
soup = BeautifulSoup(r.text, "lxml")
title = soup.find('h1', class_="post-title").a.text.strip()
print (title)Requests库
import requests
r = requests.get('http://www.santostang.com/') # 其他参数都是可选的
print ('文本编码:', r.encoding) # 如 UTF-8
print ('响应状态码:', r.status_code) # 如 200
print ('url编码:', r.url)
print ('字符串方式的响应体:', r.text) # 整个html文档
print ('字节方式的响应体:', r.content) # 自动解压gzip和deflate编码的响应数据
print ('JSON解码器:', r.json()) # Requests中内置的JSON解码器Requests请求参数
key_dict = {'key1': 'val1', 'key2', 'val2'} # 查询字符串
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.post( # get 请求可改为 post 请求
'http://httpbin.org/get', # 初始url,也可以是变量
params=key_dict, # 查询字符串
headers = headers, # 请求头参数
timeout = 0.001 # 请求超时
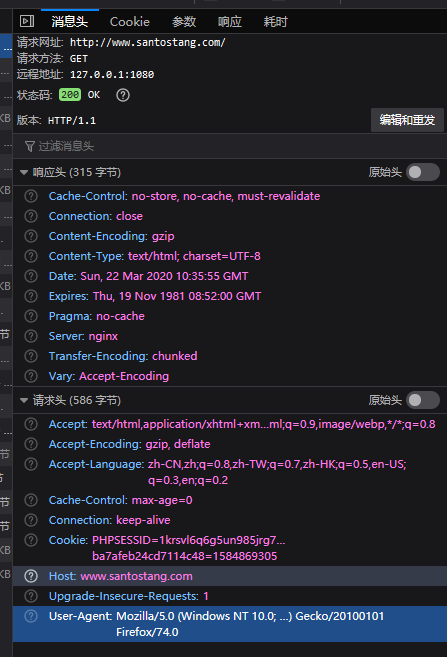
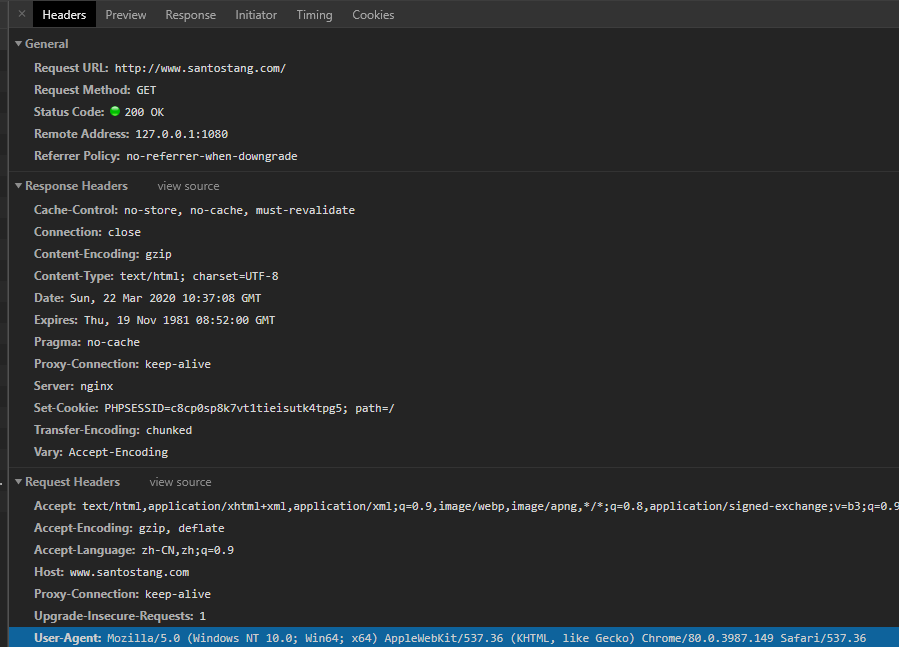
)主要请求头(Firefox & Chrome)
动态网页抓取(浏览器审查元素方案)
AJAX(Asynchronous Javascript And XML,异步 JavaScript 和 XML)
通过js展示的JS不会显示在HTML源代码中 两种方法解决:
(1)通过浏览器审查元素解析地址
(2)通过Selenium模拟浏览器抓取
通过浏览器审查元素解析地址方案
浏览器Network看抓包,一般是json文件格式
import requests
import json
link = '''https://api-zero.livere.com/v1/comments/list?callback=jQuery112407126659503587682_1584962537289&limit=10&repSeq=4272904
&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1584962537291
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
r = requests.get(link, headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 提取字符串中符合json格式的部分
json_data = json.loads(json_string) # 把字符串格式的响应体数据转化为 json 数据
comment_list = json_data['results']['parents'] # 精简列表
for eachone in comment_list:
message = eachone['content']
print (message)动态网页抓取(Selenium第三方模块)
# pip install selenium
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path = r'I:\AProjects\Jupyter\geckodriver.exe') # 电脑geckodriver地址
# driver.implicitly_wait(20) # 隐性等待,最长等20秒
browser.get("http://www.santostang.com/2018/07/04/hello-world/")
print('【link success!】')
time.sleep(5)
browser.maximize_window() #最大化窗口
for page in range(9,12):
time.sleep(10)
# 跳页、翻页部分 —— 下滑> 转换iframel> 定位> 点击 > 等待
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 下滑到页面底部 需要-700
browser.switch_to.frame(browser.find_element_by_css_selector("iframe[title='livere']")) # 转换iframe1
local = 'button[data-page="' + str(page) + '"]'
if page == 11:
local = 'button[data-page="next"]'
load_more = browser.find_element_by_css_selector(local)
load_more.click() # 点击
time.sleep(10) # 等待加载
# 获取评论部分 —— 定位> 循环获取并输出> 转换回iframel
comments = browser.find_elements_by_css_selector('div.reply-content')
for each_comment in comments:
content = each_comment.find_element_by_tag_name('p')
print(content.text)
browser.switch_to.default_content() # 转换iframe2
print('【Python Over】')Selenium模块详解
Selenium操作
选择元素
find_element_by_id :通过元素的id选择,例如:driver.find_element_by_id(‘loginForm’)
find_element_by_name :通过元素的name选择,driver.find_element_by_name(‘password’)
find_element_by_xpath :通过xpath选择,driver.find_element_by_xpath(“//form[1]”)【荐】
find_element_by_link_text :通过链接地址选择
find_element_by_partial_link_text :通过链接的部分地址选择
find_element_by_tag_name :通过元素的名称选择
find_element_by_class_name :通过元素的id选择
find_element_by_css_selector :通过css选择器选择【荐】
选择多个元素
查找多个元素,在上述的element后加上s,变成elements
其中xpath和css_selector是比较好的方法,一方面比较清晰,另一方面相对其他方法定位元素比较准确。
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
操作元素方法(常见方法)
clear 清除元素的内容
send_keys 模拟按键输入
click 点击元素
submit 提交表单
选择元素的属性
.get_attribute("href"),选择属性
.text(),选择标签内文本
iframe问题【大坑】
定位iframe
1.有id,并且唯一,直接写id
driver.switch_to_frame("x-URS-iframe")
driver.switch_to.frame("x-URS-iframe")
2.有name,并且唯一,直接写name
driver.switch_to_frame("xxxx")
driver.switch_to.frame("xxxx")
3.无id,无name,先定位iframe元素
iframe = driver.find_elements_by_tag_name("iframe")[0]
driver.switch_to_frame(iframe)
driver.switch_to.frame(iframe)
4.通常采用id和name就能够解决绝大多数问题。但有时候frame并无这两项属性,则可以用index和WebElement来定位:
- index从0开始,传入整型参数即判定为用index定位,传入str参数则判定为用id/name定位
- WebElement对象,即用find_element系列方法所取得的对象,我们可以用tag_name、xpath等来定位frame对象
要记得退回来,哪怕跳转后
自动登录程序例子
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录Selenium的高级操作——限制 css, img, js 的加载
from selenium import webdriver
fp = webdriver.FirefoxProfile()
# 在这里加限制加载的配置!
driver = webdriver.Firefox(
firefox_profile=fp, # 这里把配置写进去
executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe' # 电脑geckodriver.exe程序地址
)
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
# 控制 css
fp.set_preference("permissions.default.stylesheet",2)
# 限制图片的加载
fp.set_preference("permissions.default.image",2)
# 限制 JavaScript 的执行
fp.set_preference("javascript.enabled", False)解析网页方案
正则
BeautifulSoup第三方模块
安装
pip install bs4遍历文件树
soup.header.h3
soup.header.div.contents # contents表示内容搜索文件树(find_all 和 find)
r = requests.get(link, headers = headers)
soup = BeautifulSoup(r.text, "lxml")
soup.find(re.compile("^h"))
soup.find_all('div', class_='hd')
print(soup.find('div', class_='hd').a.span.text.strip())CSS选择器(select)
r = requests.get(link, headers = headers)
soup = BeautifulSoup(r.text, "lxml")
soup.select("header h3")
soup.select("header > h3")
print(soup.select("header h3"))lxml
数据存储方案
TXT
CSV
MySQL
MongoDB
性能改善
提升速度
反爬虫问题
解决中文乱码
登录和验证码
分布式爬虫
实战
简单demo
import requests # 请求库,伪装成浏览器访问
from bs4 import BeautifulSoup # bs库中的解析函数
# 1. 获取页面部分,print (r.text) 可得到html内容
link = 'http://www.santostang.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers = headers)
# 2. 解析html提取数据部分,print (title) 可得到提取后的内容
soup = BeautifulSoup(r.text, "lxml")
title = soup.find('h1', class_="post-title").a.text.strip() # 筛选h1且class="post-title"里面的a标签里面的文字
# 3. 存储数据部分
with open('title.txt', 'a+') as f:
f.write(title)
f.close()