李宏毅机器学习深度学习
李宏毅机器学习深度学习
目录
CNN(Convolutional Neural Network)
对应视频:P31
对应pdf:09_CNN.pdf
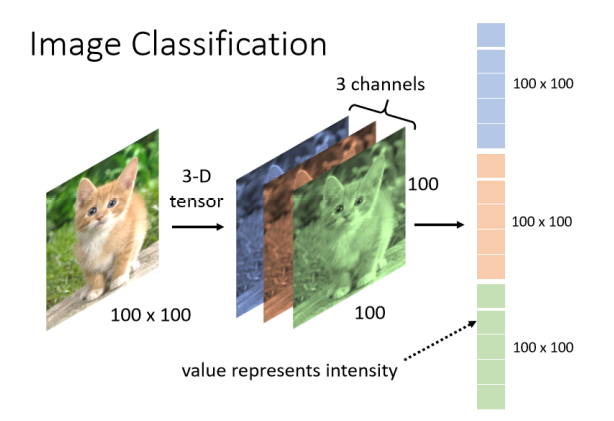
图片分类
参数量爆炸
是怎麼把一张影像当做一个模型的输入
对於一个 Machine 来说,一张图片其实是一个三维的 Tensor(张量)
如果不知道 Tensor 是什麼的话,你就想成它是维度大於 2 的矩阵就是 Tensor
一些翻译:
- Tensor,[数] 张量
- channels,通道
- pattern,模式、图案
- Receptive Field,感受野、接受野、卷积野
如果全连接(Fully Connected)
虽然随著参数的增加,我们可以增加模型的弹性,我们可以增加它的能力,但是我们也增加了 Overfitting 的风 险,有关什麼叫模型的弹性,到底 Overfitting 怎麼產生的,下週吴培元老师https://speech.ee.ntu.edu.tw/~hyle e/ml/ml2021-course-data/W14_PAC-introduction.pdf会从数学上,给大家非常清楚的证明,那我们这边就讲 概念上,如果模型的弹性越大,就越容易 Overfitting
解决方法
两种简化的方法
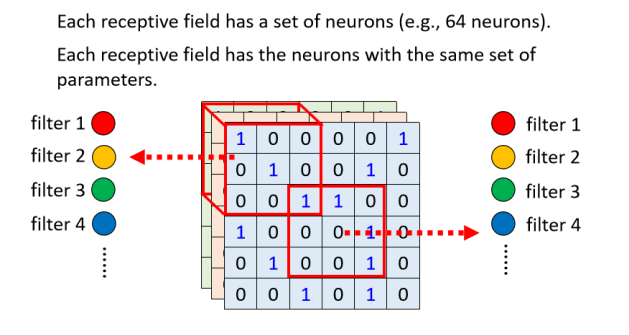
感受野
Pattern检测、感受野
是判断说现在有没有某种 Pattern 出现时,我们并不需要每 一个 Neuron都去看一张完整的图片
所以这些 Neuron 也许根本就不需要,把整张图片当作输入,它们只需要把图片的一小部分当作输入,就足以让 它们侦测某些特别关键的 Pattern有没有出现了
我们会设定一个区域叫做 Receptive Field(感受野、接受野、卷积野),每一个 Neuron 都只关心自己的 Receptive Field 裡面发生的事情就好了
一些想法:
- 我可不可以 Receptive Field 有大有小呢?可以
- 我可不可以 Receptive Field,只考虑某些 Channel 呢?可以
- 可不可以是长方形?可以!
- Receptive Field 一定要相连吗?理论上可以,但是这种特征应该很少见,二维码区域识别应该算
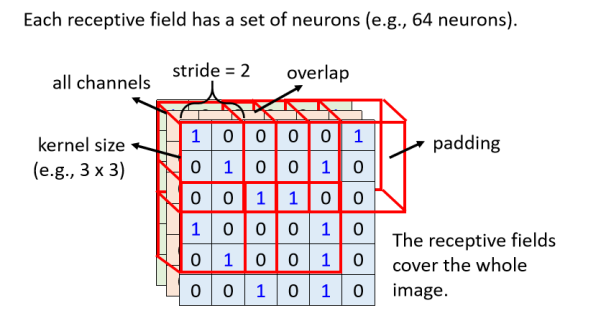
一些概念
- Kernel Size(核尺寸)
- 我们在描述一个 Receptive Field 的时候,只要讲它的高跟宽就好了。
就不用讲它的深度,反正深度一定是考虑全部的 Channel。
而这个高跟宽合起来叫做 Kernel Size - 一般3x3,也有5x5,7x7
- 我们在描述一个 Receptive Field 的时候,只要讲它的高跟宽就好了。
- Stride(步幅)
- Stride 是一个你自己决定的 Hyperparameter,但这个 Stride 你往往 不会设太大,往往设 1 或 2 就可以了
- 超出的就不要,或者做padding
- Padding(填充,补值)
共享参数
同样的 Pattern,它可能会出现在图片的不同区域裡面
我们真的需要每一个守备范围,都去放一个侦测鸟嘴的 Neuron 吗?不需要!
放在影像处理上的话,我们能不能够让,不同 Receptive Field 的 Neuron共享参数,也就是做 Parameter Sharing权值共享
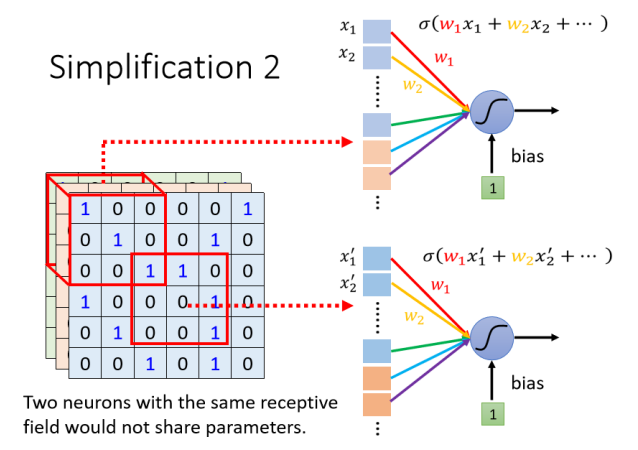
位置不同但可以使用相同的权重!
具体上,怎么去共享参数?
你完全可以自己决定,而这个是你可以自己决定的事情,但是接下来还是要告诉大家,常见的在影像辨识上面的共享的方法,是怎麼设定的
实每一个 Receptive Field都只有一组参数而已,那这些参数有一个名字,叫做 Filter(卷积核、过滤器、滤波器)
Pooling 池化层
把一张大的图片缩小,这是一隻鸟,这张小的图片看起来还是一隻鸟

Pooling 这个东西啊,它本身没有参数,所以它不是一个 Layer,它裡面没有 Weight,它没有要 Learn 的东西
所以 有人会告诉你说 Pooling 比较像是一个 Activation Function,比较像是 Sigmoid , ReLU 那些,因為它裡面是 没有要 Learn 的东西的,它就是一个 Operator,它的行為都是固定好的,没有要根据 Data 学任何东西
Pooling 其实也有很多不同的版本,我们这边讲的是 Max Pooling
MaxPooling
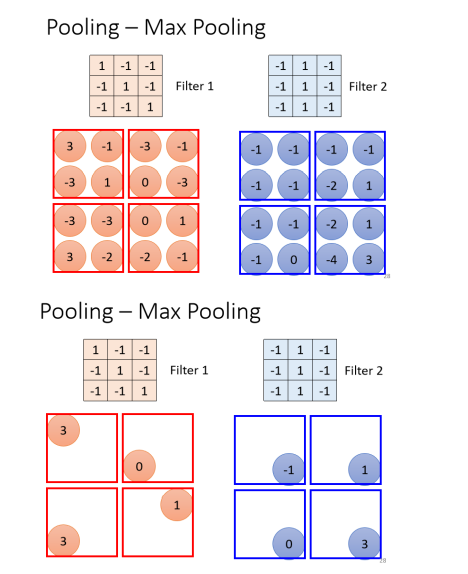
在这个例子 裡面就是 2×2 个一组,每一组裡面选一个代表,在 Max Pooling 裡面,我们选的代表就是最大的那一个
一般在实际上,Convolution和Pooling会交替使用
Pooling会带来一点图片损耗,最近运算能力越来越强,有的网络的设计甚至不用Pooling,Full Convolution
整理总结
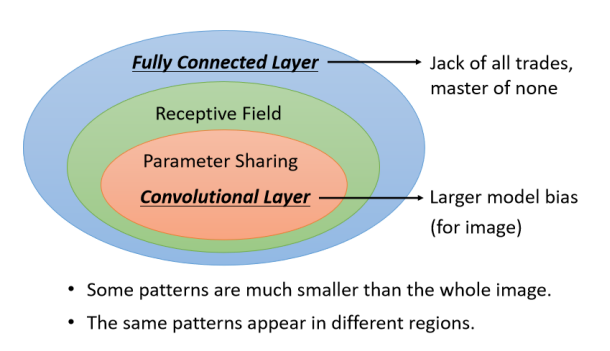
我们加了 感受野 和 参数共享 来限制全连接,变成卷积层 CNN。
CNN 的弹性小了很多,Bias 比较大
可能有小伙伴会说 Model Bias 比较大 不是一件坏事吗? Model Bias 大,不一定是坏事
- 因為当 Model Bias 小,Model 的 Flexibility 很高的时候,它比较容易 Overfitting。
- 虽然Fully Connected Layer可以做各式各样的事情,它可以有各式各样的变化,但是它可能没有办法在任何特定的任务上做好
- Convolutional Layer它是专门為影像设计的。刚才讲的 Receptive Field 参数共享,这些观察 都是為影像设计的,所以它在影像上仍然可以做得好。
虽然它的 Model Bias 很大,但这个在影像上不是问题。但是如果它用在影像之外的任务,你就要仔细想想那些任务有没有我们刚才讲的影像用的特性
卷积层
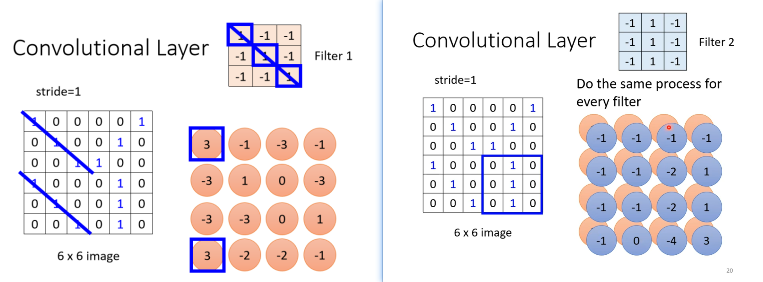
Convolutional 的 Layer 就是裡面有很多的 Filter
一个 Convolutional 的 Layer 裡面就是有一排的 Filter,一个 Filter 的作用就是要去图片裡面某一个 Pattern
卷积操作、特征图谱
把 Filter 裡面所有的值,跟左上角这个范围内的 9 个值做相乘,也就是把这个 Filter 裡面的 9 个值,跟这个范围裡 面的 9 个值呢,做 Inner Product,做完是 3
注意!在此处卷集运算中,老师讲的内积,不要理解为线性代数中矩阵的乘法,而是filter跟图片对应位置的 数值直接相乘,所有的都乘完以后再相加
假设有64个过滤器,那么我们就得到 64 群的数字了。
这一群数字啊,它又有一个名字,它叫做 Feature Map(特征图谱)
如果我们的 Filter 的大小一直设 3 × 3,会不会让我们的 Network,没有办法看比较大范围的 Pattern 呢?不会
例如当我们看这 3 × 3 的范围的Feature Map时候,其实是考虑了一个 5 × 5 的范围
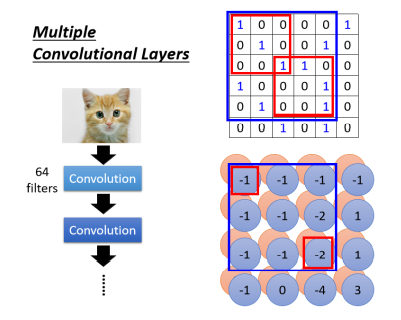
所以 Network 够深,你不用怕你侦测不到比较 大的 Pattern,它还是可以侦测到比较大的 Pattern
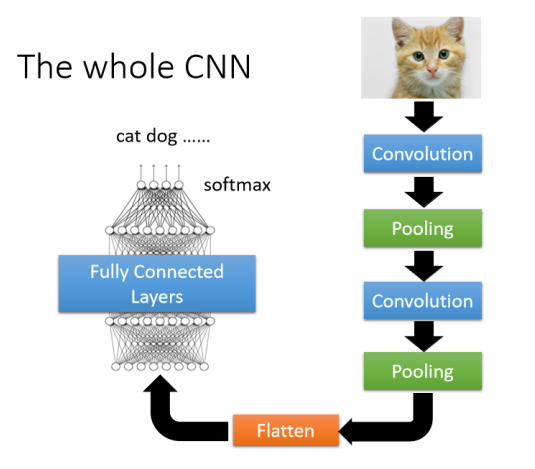
整个CNN
怎么使用CNN下围棋?
可以将棋盘表示成一个的二维向量作为输入,然后可以变成一个的多分类问题
CNN会比Fully-connected的效果更好。AlphaGo的原始论文里说,每一个Pixel,它是用 48 个 Channel 来 描述
有一点与图像识别不同:
在做影像的时候我们说我们都会做 Pooling,一张影像做 Subsampling 以后, 并不会影响我们对影像中物件的判读
但是棋盘是这个样子吗?你可以把棋盘上的奇数行跟偶数列拿掉,还是同一个棋局吗?
下围棋这麼精细的任务,你随便拿掉一个 Column 拿掉一个 Row,整个棋整个局势就不一样了
局限性
CNN,没有办法处理影像放大缩小,或者是旋转的问题
那就是為什麼在做影像辨识的时候,往往都要做 Data Augmentation