Markdown-it 插件设计原则
Markdown-it 插件设计原则
我记得这篇的第一章是转载来的,但转载的是哪篇来着?
解析原理2
介绍
markdown-it是一个用来解析markdown的库,它能够将markdown代码编译为html代码
原理
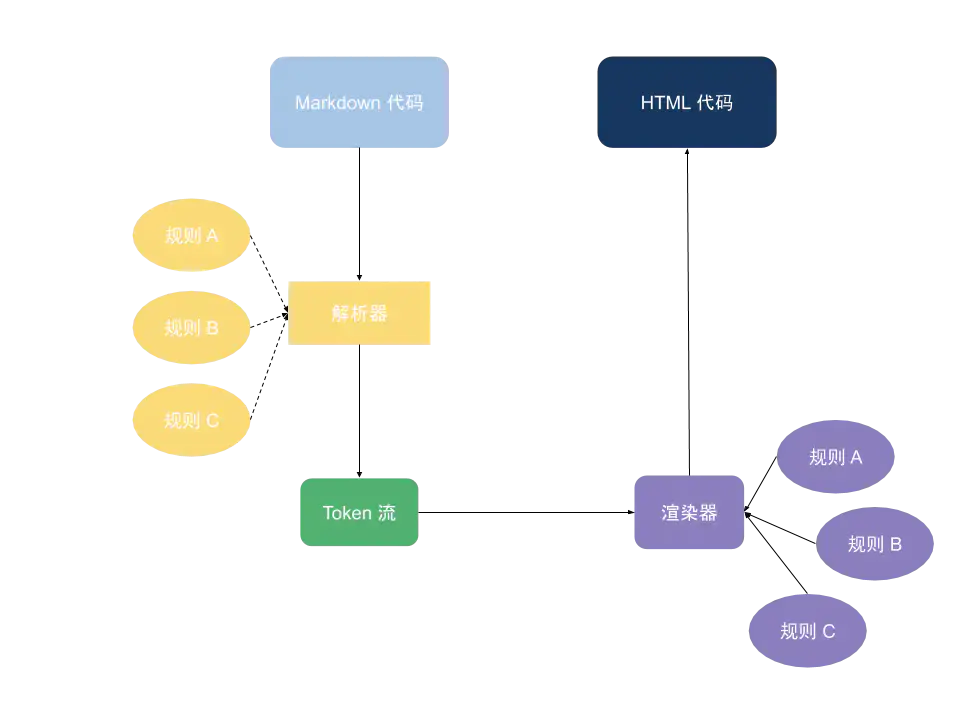
架构图
三种模式
markdown-it 提供了三种模式:
- commonmark
- 对应:最严格 解析模式
- default
- 对应:GFM 解析模式
- zero
- 对应:最宽松 解析模式
解析 - 两种规则
markdown-it 的解析规则 (rules) 可分为两种:
- 块(block):
MarkdownIt.block对应的是解析块规则的ParserBlock - 内联(inline):
MarkdownIt.inline对应的是解析内联规则的ParserInline
解析 - 顺序
解析的过程是,首先创建一个 Core Parser,这个 Core Parser 包含一系列的缺省 rules。这些rules 将顺序执行,每个 rules 都在前面的 Tokens 的基础上,要么修改原来的 Token,要么添加新的 Token。这个 rules 的链条被称为 Core Chain。
Tokens
经过解析后我们得到的结果不是一颗 AST 树,而是一个数组,markdown-it 称之为 token 流。为什么呢?
官方解释是:
- Tokens 是一个简单的数组。(AST 是一个对象)
- 打开的标签和关闭的标签可以隔离。
- 将 “内联容器(inline container)” 作为一种特殊的 block token 对象。
- 它有嵌套的 tokens,如粗体,斜体,文本等等。
- 这样做有什么好处呢?这样就可以并行处理 block 和 inline 类型的 token 了。
比如通过markdown-it我们可以把 # change! 转化为以下内容:
[
{
"type": "heading_open", // heading_open,#号,#
"tag": "h1",
"attrs": null,
"map": [
0,
1
],
"nesting": 1,
"level": 0,
"children": null,
"content": "",
"markup": "#",
"info": "",
"meta": null,
"block": true,
"hidden": false
},
{ // inline,内容,change!
"type": "inline",
"tag": "",
"attrs": null,
"map": [
0,
1
],
"nesting": 0,
"level": 1,
"children": [
{
"type": "text",
"tag": "",
"attrs": null,
"map": null,
"nesting": 0,
"level": 0,
"children": null,
"content": "change!",
"markup": "",
"info": "",
"meta": null,
"block": false,
"hidden": false
}
],
"content": "change!",
"markup": "",
"info": "",
"meta": null,
"block": true,
"hidden": false
},
{
"type": "heading_close", // heading_close
"tag": "h1",
"attrs": null,
"map": null,
"nesting": -1,
"level": 0,
"children": null,
"content": "",
"markup": "#",
"info": "",
"meta": null,
"block": true,
"hidden": false
}
]渲染器
它会遍历所有 token,将每个 token 传递给与 token 的 type 属性同名的规则。
markdown-it 内置了九种规则:
- 围栏
- 行内代码
- 代码块
- 块 html
- 行内 html
- 图片
- 硬换行
- 软换行
- 文本
type 属性不在内置规则的 token 将会被被传入 renderToken 中当一个普通 token 处理。MarkdownIt.renderer.render 和 MarkdownIt.renderer.renderInline 分别对应按照 块规则 和 内联规则 生成 HTML 代码。
而在 MarkdownIt.renderer 中有一个特殊的属性:rules,它代表着对于 token 们的渲染规则,可以被使用者更新或扩展:
var md = require('markdown-it')();
md.renderer.rules.strong_open = function () { return '<b>'; };
md.renderer.rules.strong_close = function () { return '</b>'; };
var result = md.renderInline(...);比如这段代码就更新了渲染 strong_open 和 strong_close 这两种 token 的渲染规则
Token vs AST
为什么不是 AST?因为我们的任务不需要它。我们遵循 KISS 原则。 如果你愿意的话 - 你可以在没有渲染器的情况下调用解析器并转换 tokens 流到 AST。
GPT4:
makrdown-it 为什么选用更底层的tokens存储数据,与传统的AST相比要什么优点和缺点?
markdown-it 使用更底层的 tokens 存储数据是为了提供一个更高的性能和更好的可扩展性。相比传统的 AST,tokens 有以下优点和缺点:
优点
- 性能: tokens 提供了更高的解析速度,因为它们不需要创建一个复杂的树形结构。这使得 markdown-it 在处理大量文本时更为高效。
- 灵活性: 由于 tokens 是线性排列的,它们可以更轻松地进行修改、移动和替换,而这在树形结构中会更为复杂。
- 可扩展性: tokens 结构使得 markdown-it 更易于扩展和添加新的功能。开发者可以轻松地为 markdown 添加自定义的规则和渲染器,而不用担心破坏原有的 AST 结构。
- 简化解析过程: 与 AST 相比,tokens 提供了一种更简单的方式来解析和生成 HTML,因为它们可以直接映射到 HTML 标签和属性。
缺点
- 可读性: 由于 tokens 是线性的,它们可能不如 AST 结构那么直观。对于开发者来说,理解和调试 tokens 可能需要更多的时间和精力。
- 维护成本: 与 AST 相比,tokens 结构可能在未来需要更多的维护工作。这是因为 tokens 实现了较多的低级细节,可能需要更多的修改来适应未来规范的变化。
总之,markdown-it 选择使用 tokens 进行数据存储,是为了追求更高的性能、灵活性和可扩展性。尽管 tokens 结构在可读性和维护成本方面存在一定的缺点,但在许多场景下,这些优点使得使用 tokens 成为了更好的选择。