VS
VS
目录
安装
费用
占用
系统驱动器(这个很烦)
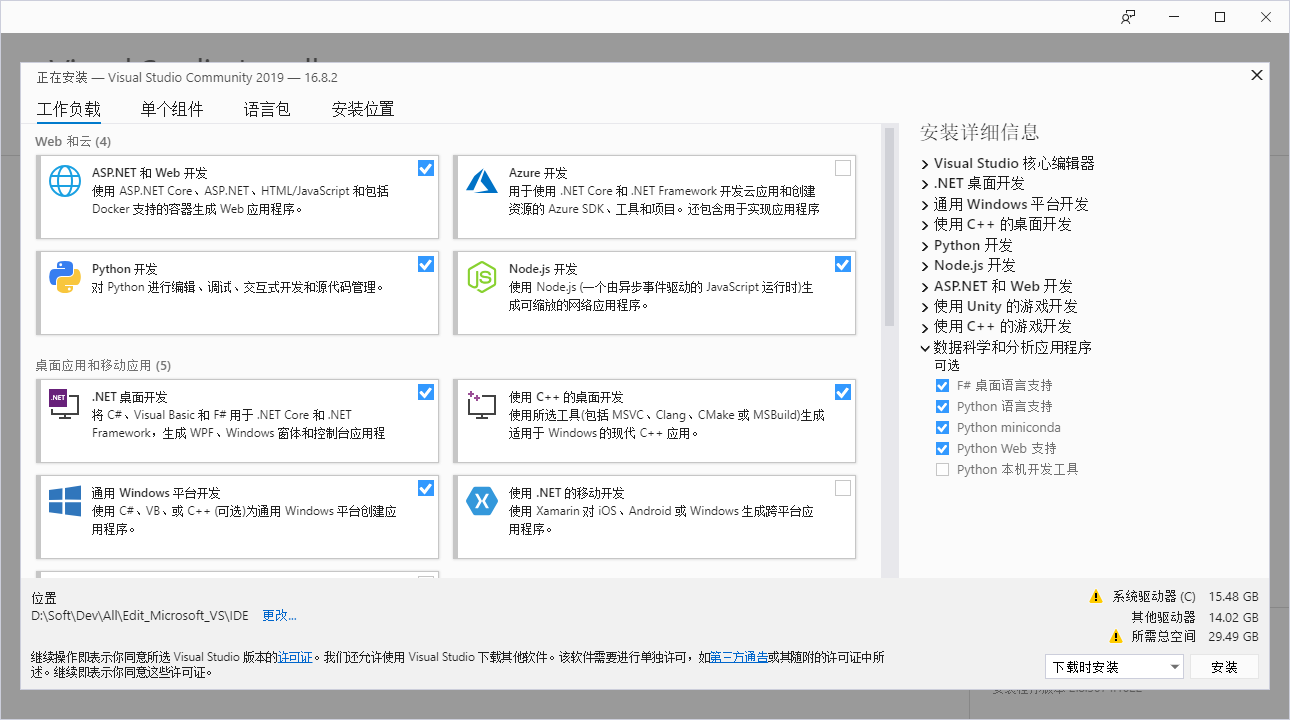
VS安装后如何添加工作负载
方法1
重新打开安装程序,会出现添加删除组件的界面,勾选即可
方法2
打开软件时选择菜单栏的 工具 > 获取工具和功能
开发辅助工具(好用的)
编辑器工具
文档工具
- 如何查看C/C++头文件内容?
- 光标选中头文件所在行 > 右键 > 转到文档(F12)
- 定义的函数工具
- 光标选中函数定义所在行 > 右键 >
- 速览定义(Alt+F12),【弹出小窗口的方式】可以快速浏览函数原型、函数所属的头文件
- 转到定义(F12),【显示文件列表的方式,可跳转至对应行】
- 转到声明(Ctrl+F12),【显示文件列表的方式,可跳转至对应行】,好像和上一个差不多啊
- 查找所有引用(Shift+F12),【显示文件列表的方式,可跳转至对应行】
- 光标选中函数定义所在行 > 右键 >
打开
有个很坑的点,例如我想用VS打开一个CLion项目,或CMakeList.txt的其他项目。
一开始打开的选项里只有打开sln等,或直接打开文件夹。但都是错的。
要先按 "继续,但无需代码",进去主页面后再按 文件>打开,此时才能看到一个 CMake 的选项,此时才能打开CMake
编译
2022 社区版为例,顶部工具栏有几个编译相关的工具
- 设备/部署:本地计算机
- 工具集:下拉 > 管理配置,即可设置。可设置:
- minGW、MSVC、Clang 等
- Debug / Release / Other
- x64 / x86 等
- 输出路径
- 目标:Sln / CMakeLists的设置多个目标 (可执行文件或库)
- Debug/Release
工具集补充:
- 与CLion不同,这会生成一个CMakeSetting.json。而在 工具 > 选项 > CMake > 常规 中,有个选项:CMake配置文件
- 始终使用 CMake 预设 (CMakePresets.json)
- 如果可用,请使用 CMake 预设,否则使用 CMakeSettings.json (默认)
- 从不使用 CMake 预设
- 而 CMakePresets.json 是更通用的一种格式,推荐优先使用,详细内容见 CMakePresets.json 的相关笔记
调试
VS调试工具是出了名的好用,比起其他IDE软件有更多更强大的功能
参考
调试工具
参考
Step Into、Step Over,Step Out区别
| 调试方式 | 快捷键 | 作用/区别 |
|---|---|---|
| Step Into | F11/F5 | 单步执行,遇到子函数就进入并且继续单步执行 |
| Step Over | F10/F6 | 在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行, 而是将子函数整个执行完在停止,也就是把子函数整个作为一步 |
| Step Return | Shift+F11/F7 | 在单步执行到子函数内时,用Step Return就可以执行完子函数余下部分,并返回上一层函数 |
括号左侧为 visual studio 的快捷键,右侧为 eclipse 的快捷键。
悬停鼠标查看表达式
实时改变值
设置下一条语句
编辑然后继续
方便的监视窗口
带注释的反汇编
带有栈的线程窗口
条件断点
内存窗口
转到定义
命令窗口
调试工具 - 高级
参考
- 【博客园】5 个非常实用的 vs 调试技巧(Main)
并行堆栈
打开方式
调试 -> 窗口 -> 并行堆栈 (Call Stack)
快捷键:是 ctrl + shift + d, s(按住 ctrl + shift,再按 d,松开 ctrl, shift 后再按 s) (VS的快捷键按起来确实奇怪)
作用
(调用堆栈窗口 的进化版 —— 并行堆栈窗口)
我们可以通过调用堆栈窗口查看当前线程的调用栈,局限是只能查看某个线程的调用栈,要想查看每个线程的调用栈得切来切去的,太麻烦。 如果我们想同时查看多个线程的调用情况,我们可以使用并行堆栈窗口。
顾名思义,并行堆栈窗口可以同时查看多个线程的调用栈。 如果程序中的某个线程死循环了,我们想确定是哪个,这时候可以中断到 vs 中,然后打开并行堆栈窗口进行查看,基本上可以很快定位到出问题的代码。
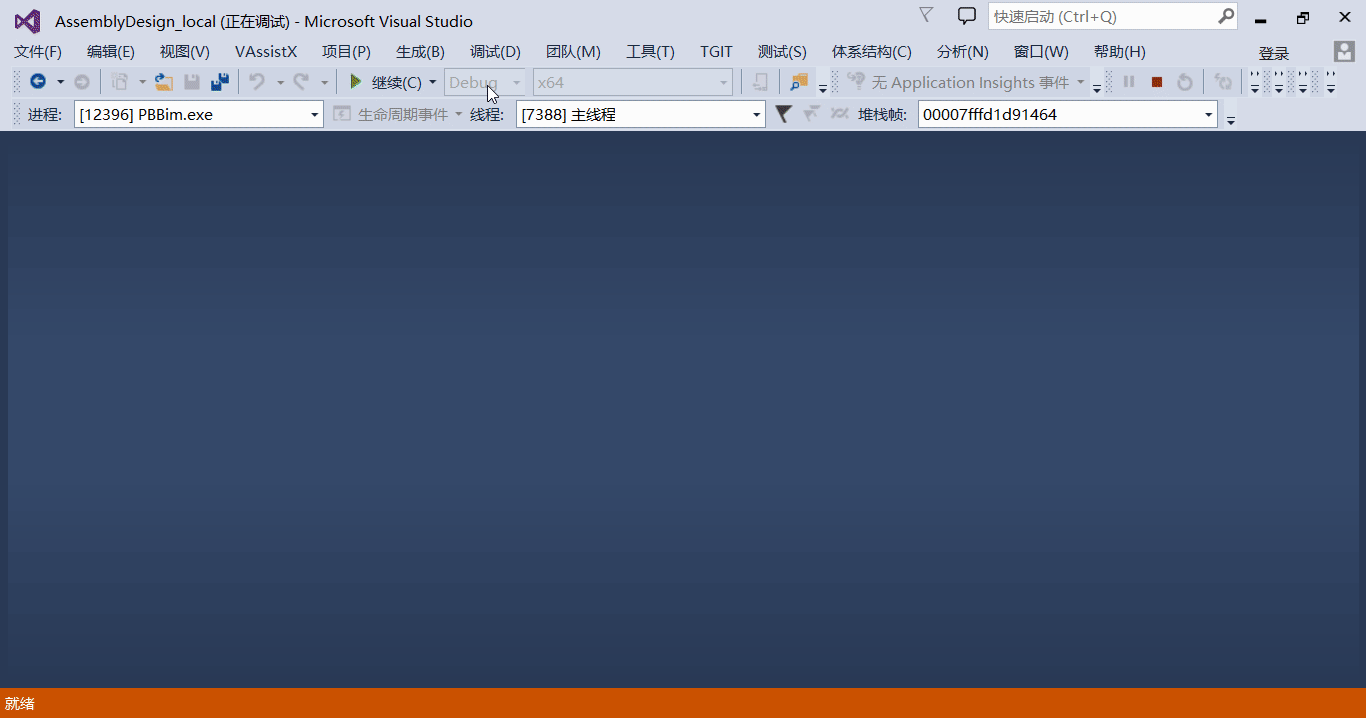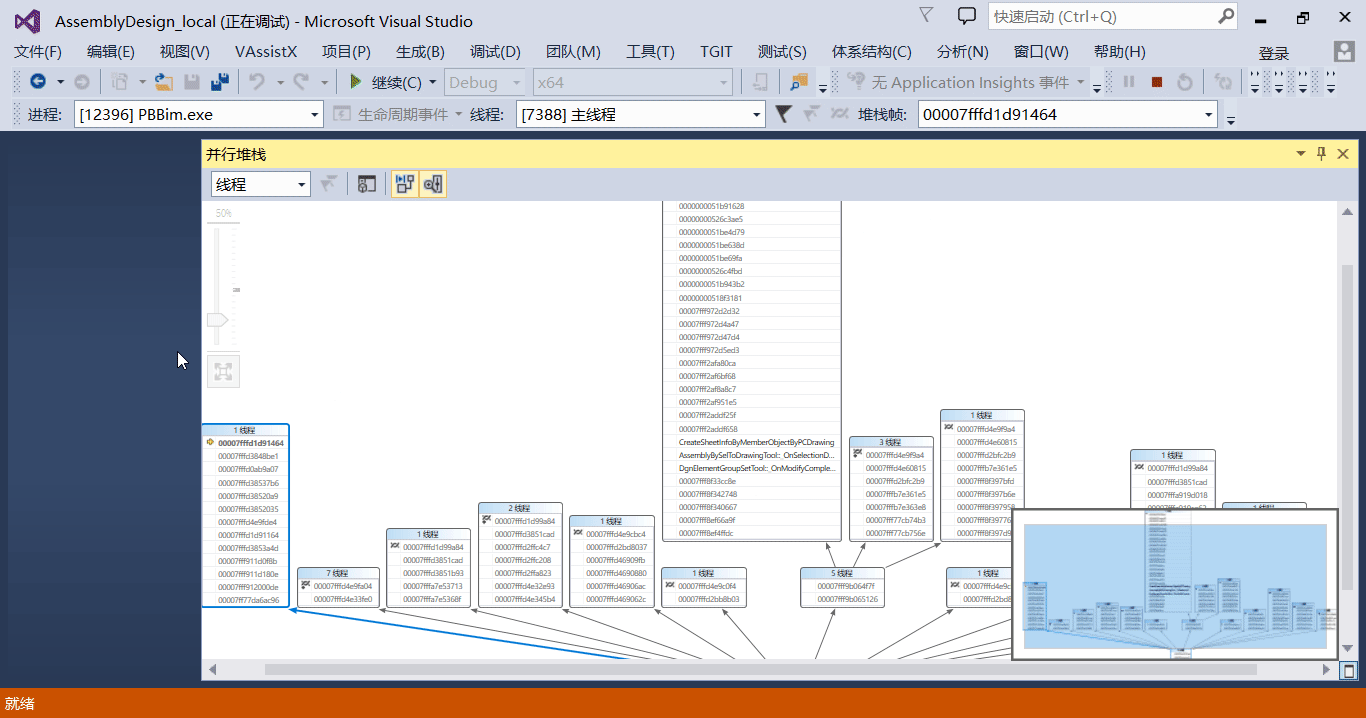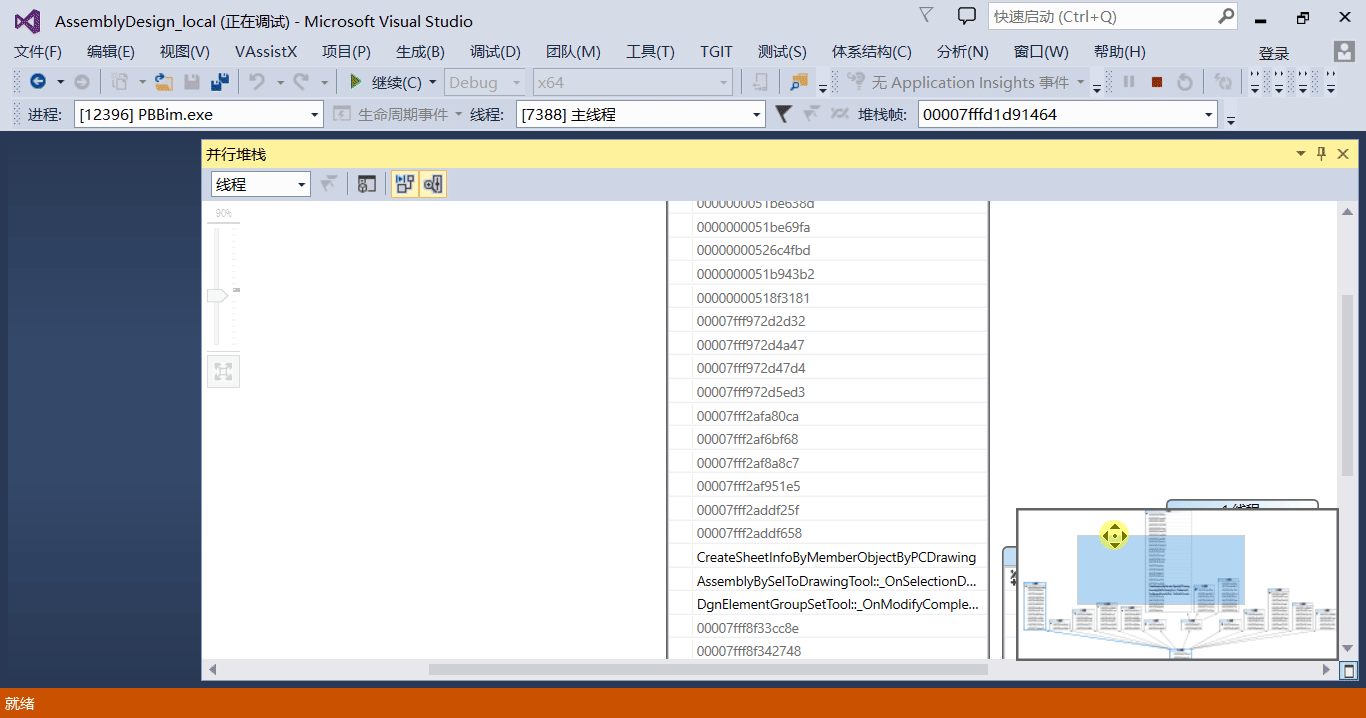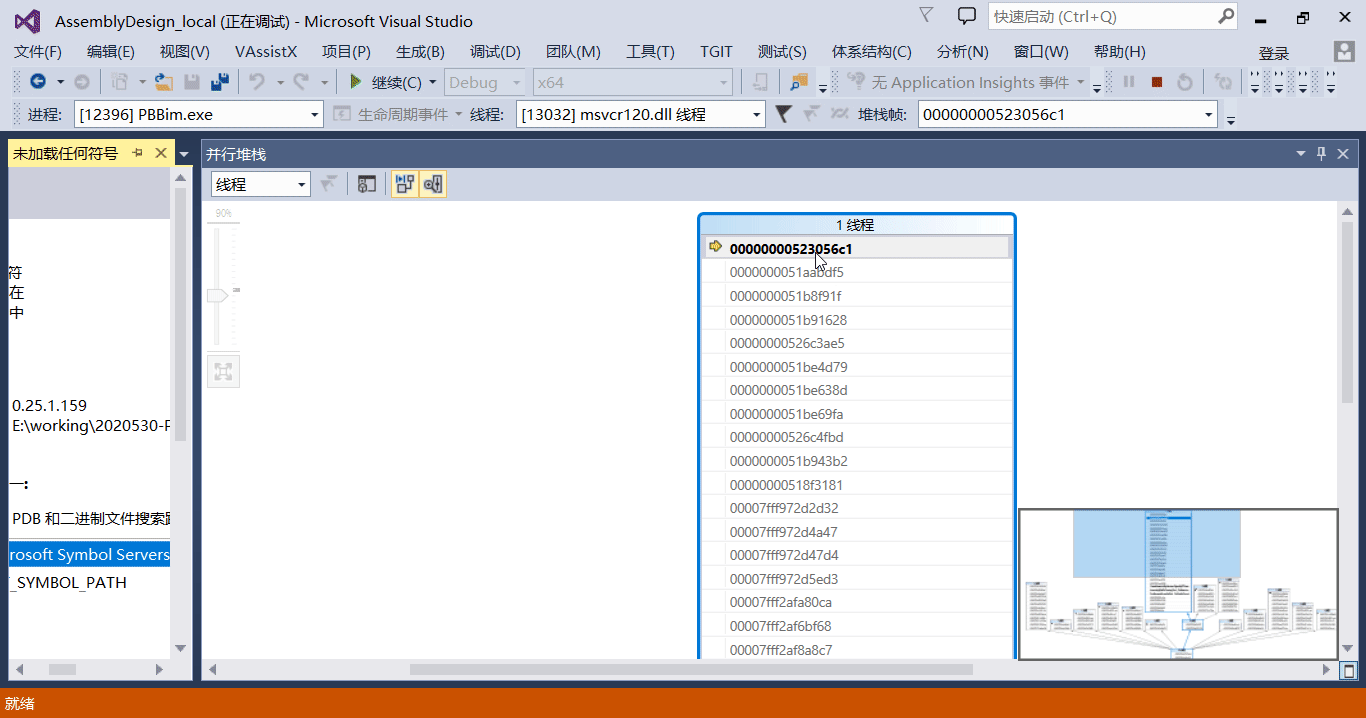
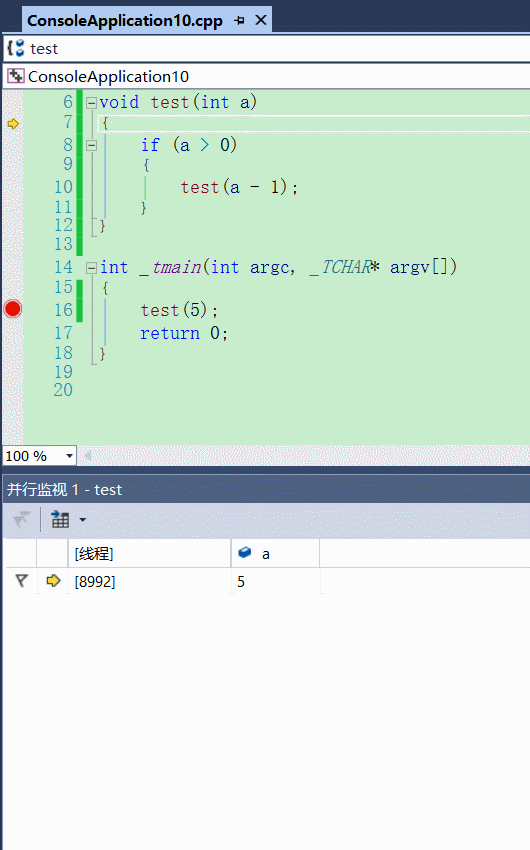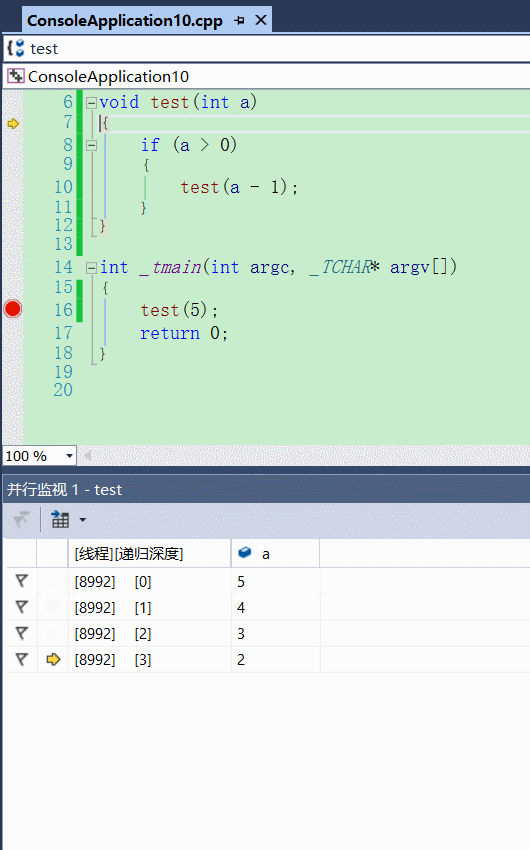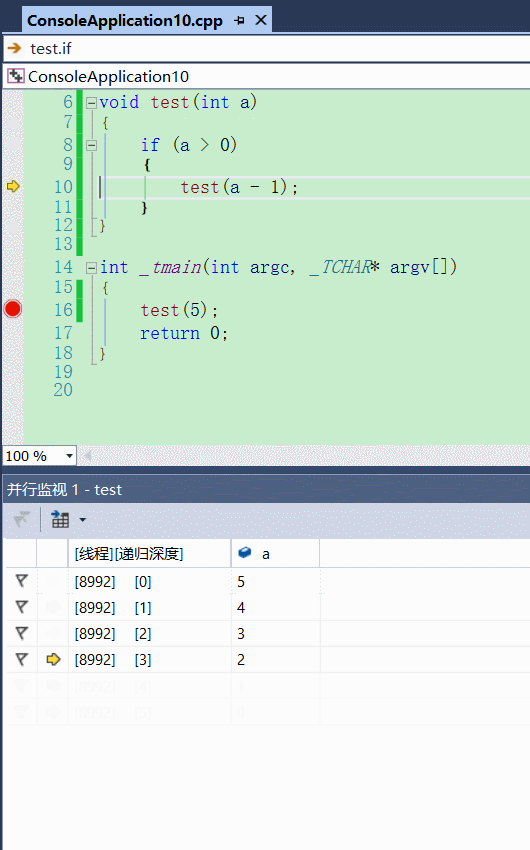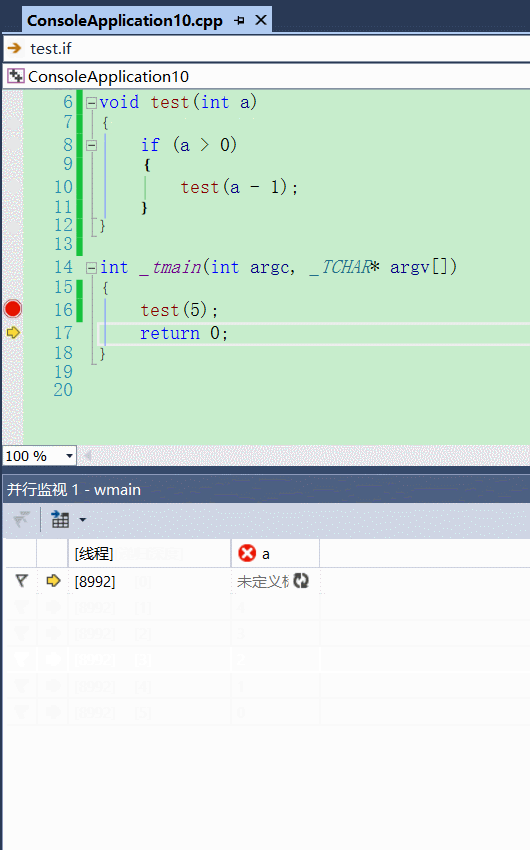
并行监视
打开方式
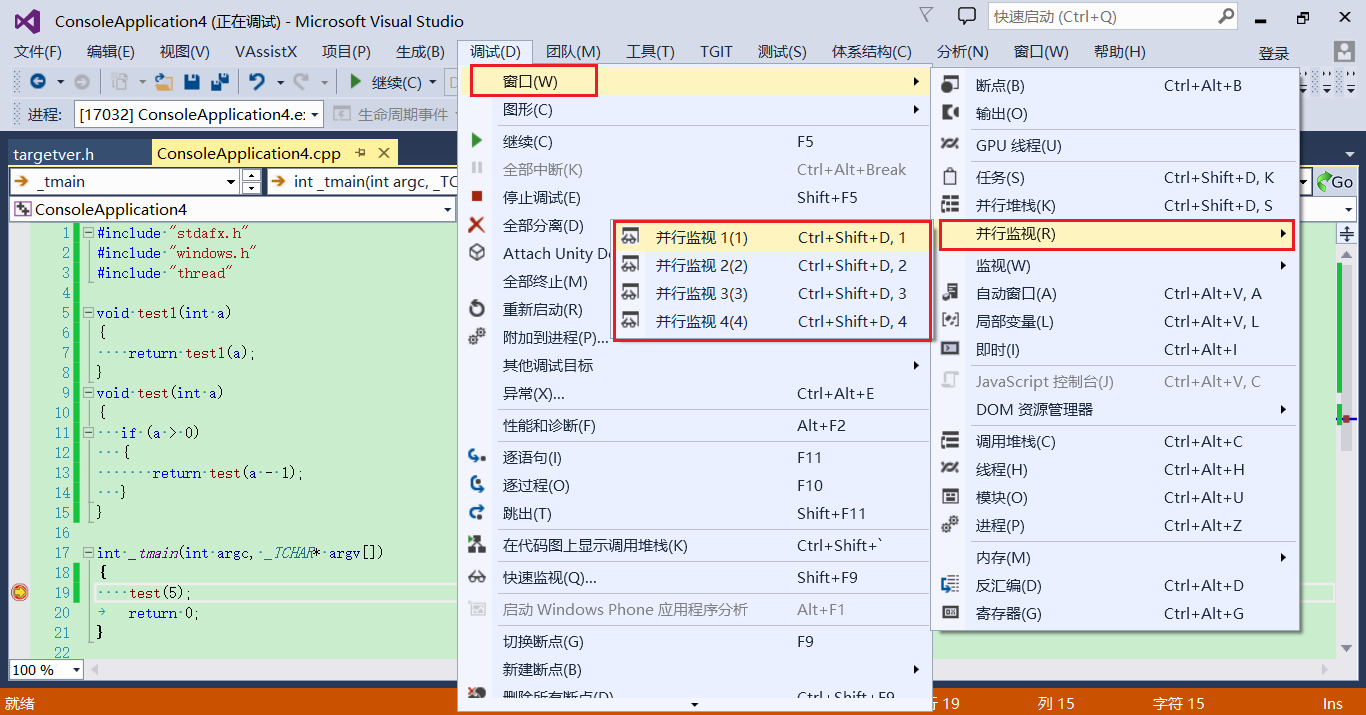
菜单 -> 调试 -> 窗口 -> 并行监视 -> 并行监视1/2/3/4
即可打开对应的并行监视窗口。和监视窗口一样可以同时打开四个。
在 vs2013 中对应的快捷键是 ctrl + shift + d, 1/2/3/4 。注意是按住 ctrl + shift,再按 d,松开 ctrl, shift 后再按 1/2/3/4。
作用
(监视窗口 的进化版 —— 并行监视窗口)
相信,大家经常使用监视窗口查看变量,当我们想查看每个栈帧的局部变量的时候,我们需要切换到对应栈帧才能看到对应的值,是不是比较麻烦? 并行监视窗口了解下
| 调用方法 | 作用效果(单监视窗口) |
|---|---|
 |  |
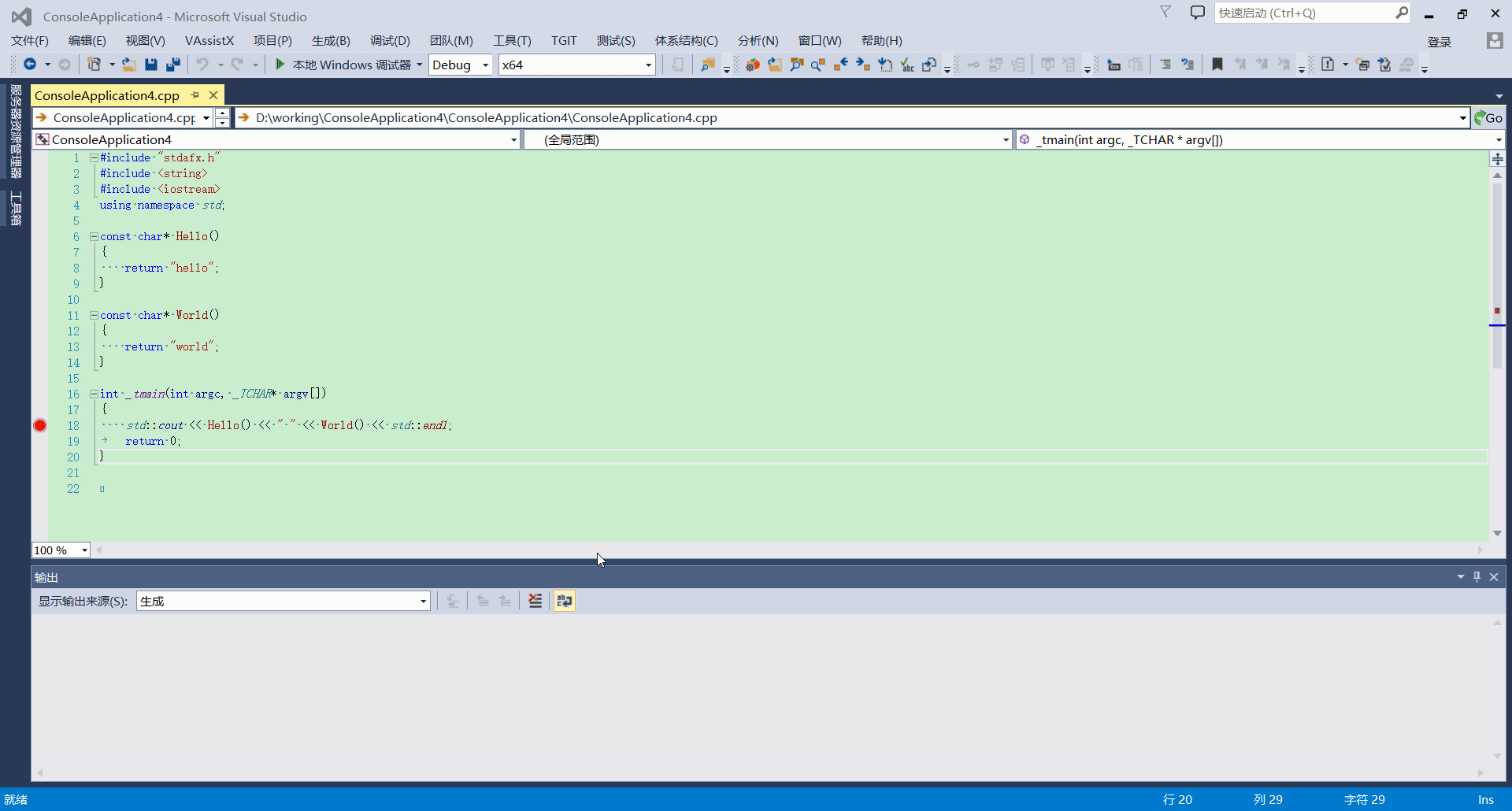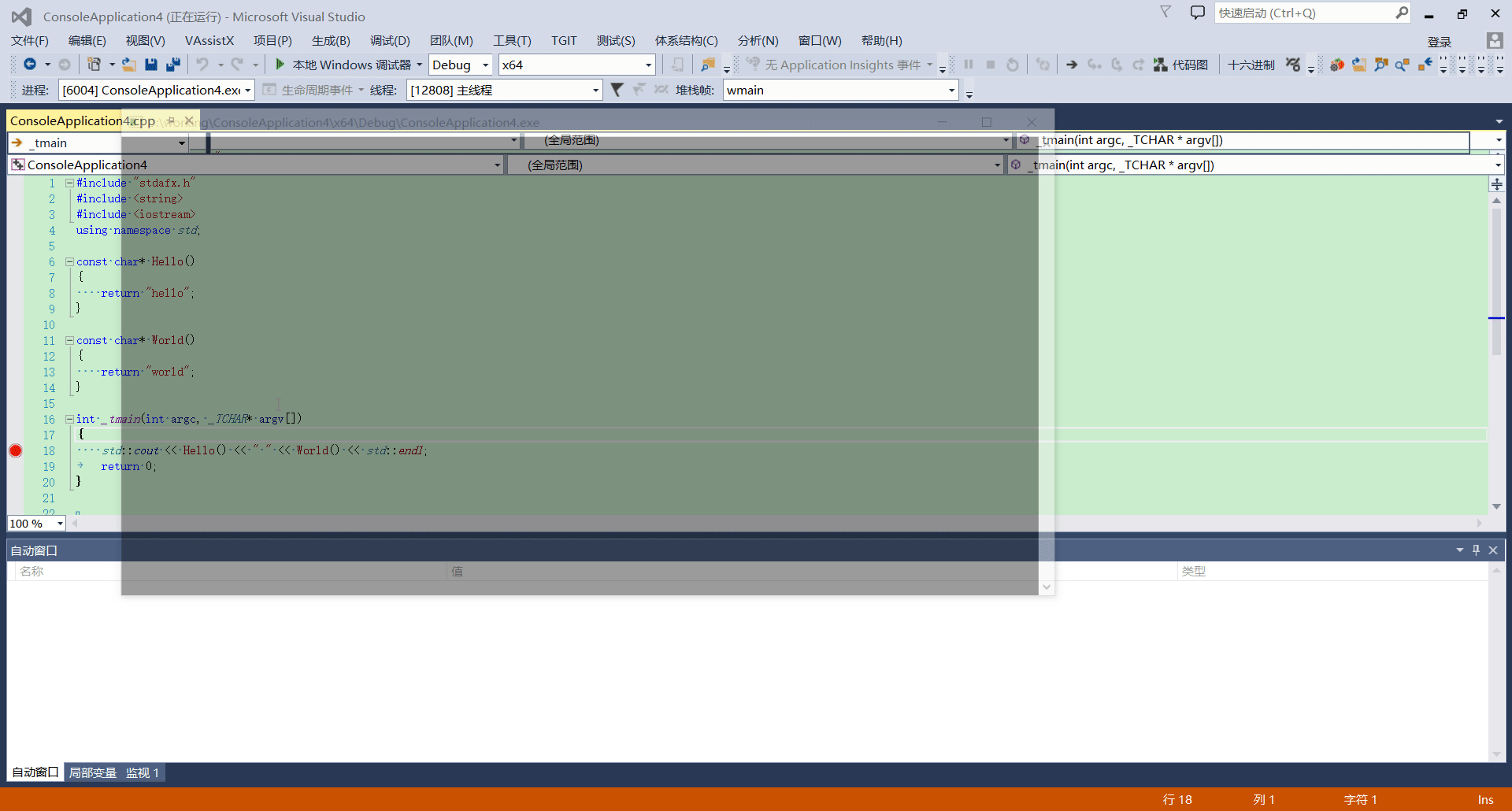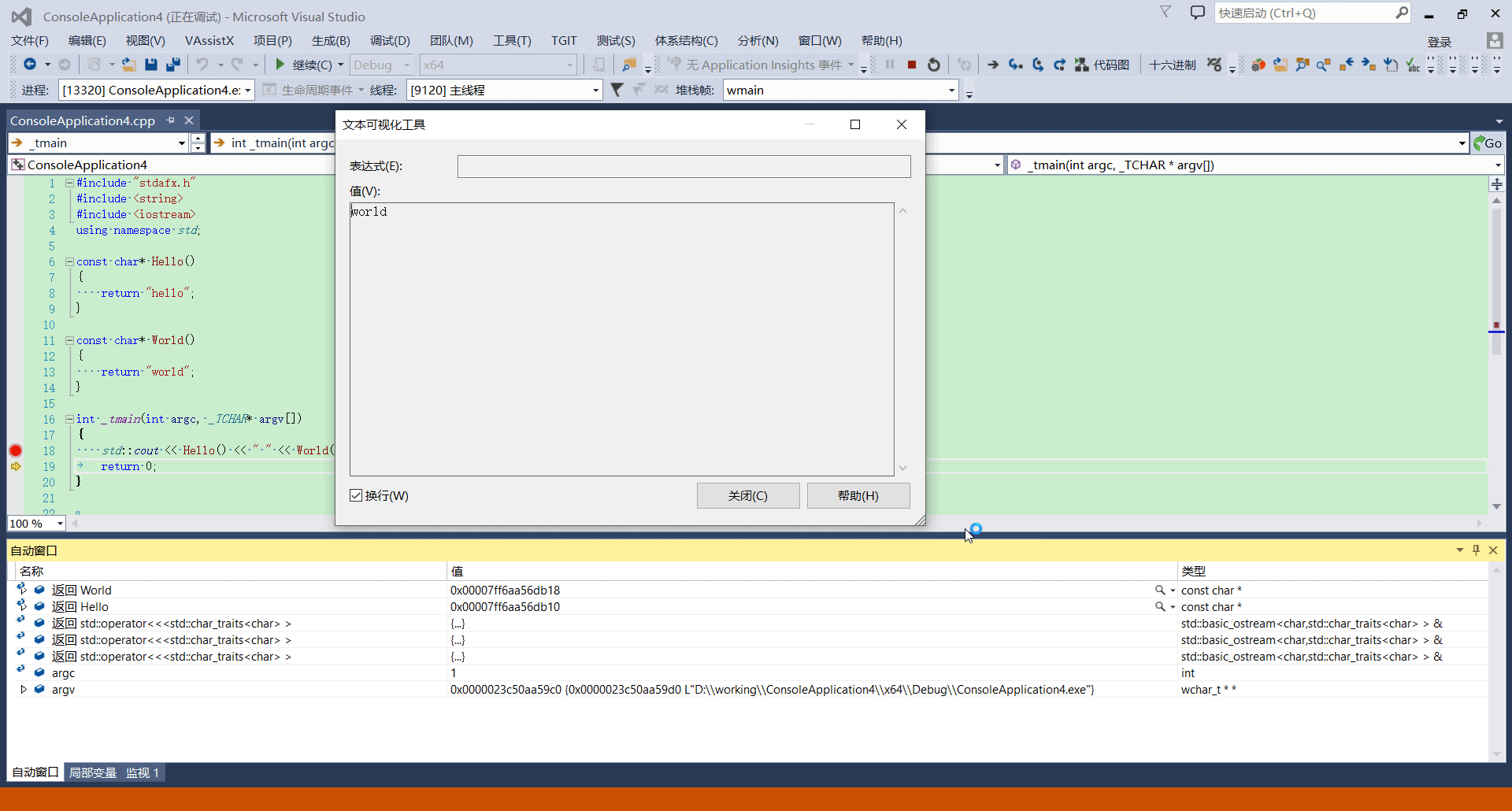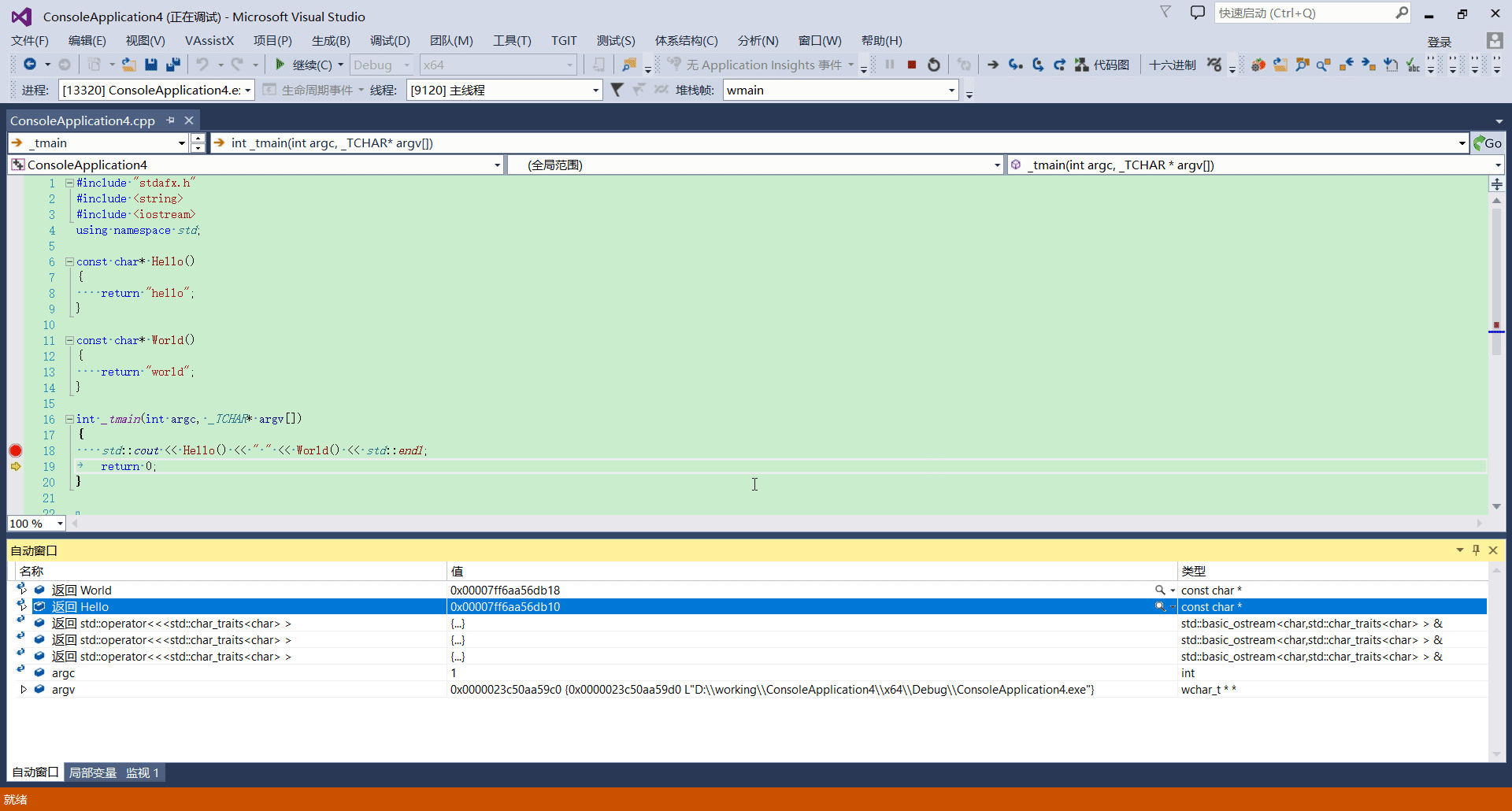
自动窗口
打开方式
菜单 -> 调试 -> 窗口 -> 自动窗口
快捷键: ctrl + alt + v, s 。注意是按住 ctrl + alt,再按 v,松开 ctrl, alt 后再按 s。
作用
除了可以查看函数参数,局部变量的值意外,更有用的功能是查看函数调用的返回值
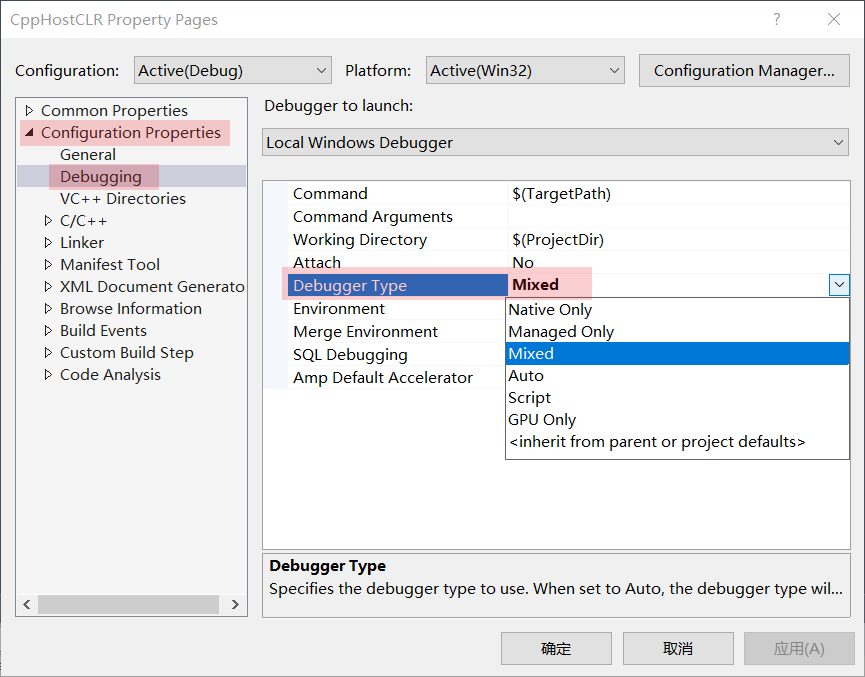
混合调试
打开方式
通过 F5 调试时的设置方法
通过附加进程进行调试时的设置方法
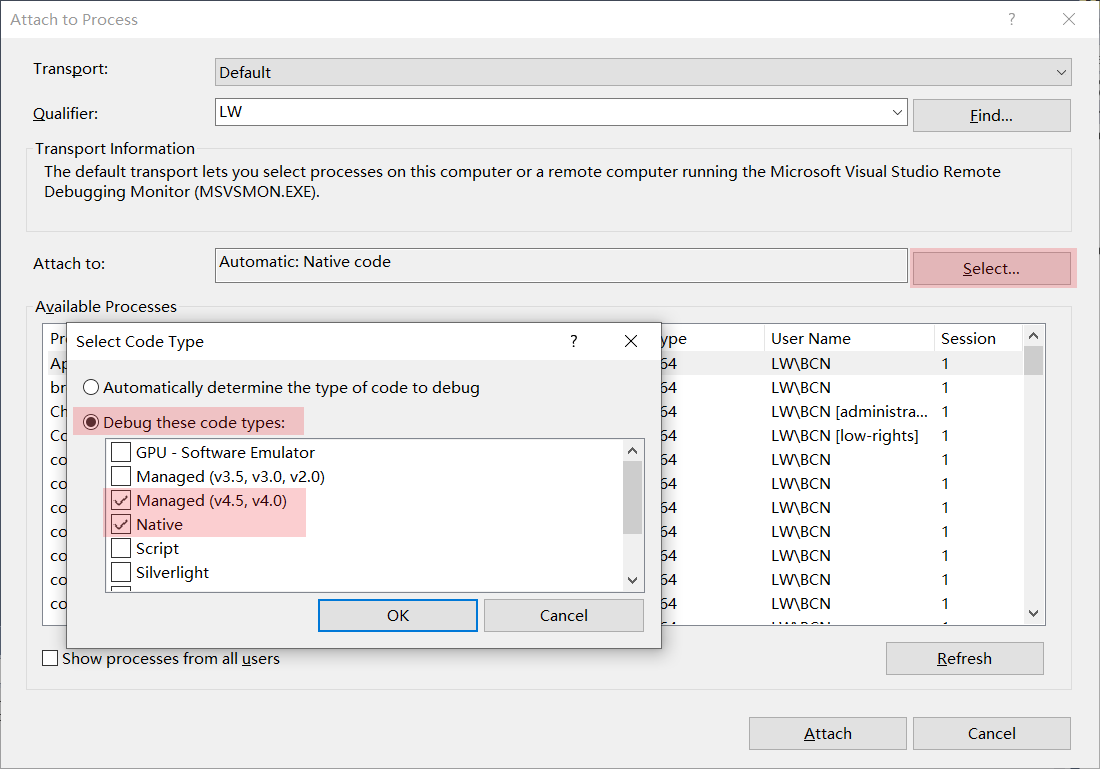
务必注意: 有时候我们设置断点不生效,可以检查一下调试方式是否选对了。如果我们只想调试 C++ 代码,可以只勾选 Native,如果只想调 .NET 代码,可以根据实际情况勾选 Managed(v4.5, v4.0) 或者 Managed(v3.5, v3.0, v2.0),如果都想调那就都勾选
作用
当我们需要调试的程序中有 .NET 代码,也有 c++ 代码时,开启混合调试非常有必要
使用断点修改变量的值
注意:
1、 表达式不要加分号!!!
2、 高版本的 vs 才支持,vs2019 亲测有效
作用
相信大家在调试的时候都设置过断点,但是你是否知道我们可以在调试的时候通过断点来改变变量的值
调查问题时,想手动修改值来验证一下我们的想法是否正确,但是又不想修改代码,也不想中断下来后,手动修改,因为可能需要手动修改 N 次,改过的小伙伴儿应该有体会。我们可以通过这个小技巧来自动帮我们改变变量的值
踩坑
Debug和Release区别
区别
- Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序
- Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用
- Debug 和 Release 的真正区别,在于一组编译选项
栈的方向
从大到小分配的栈的结构
Linux进程的虚拟地址空间设计:(地址从下往上增大)
| 虚拟地址空间 | 补充说明 |
|---|---|
| 内核虚拟内存 | 【顶部区域】不允许应用程序读写和调用,必须通过调用内核来执行这些操作 |
| 用户栈 (往下增长) | 运行时创建 【动态大小】每次调用函数栈增长,函数返回时栈会收缩 |
| ↕ | |
| 共享库的内存映射区域 (往上增长) | 【动态大小】存放像C标准库和数学库这样共享库代码和数据的地方 |
| ↑ | |
| 运行时堆 (往上增长) | 运行时由malloc创建 【动态大小】调用malloc和free这样的C标准库函数时可动态扩展和收缩 |
| 读/写数据 | 从hello可执行文件加载进来的程序代码和数据 |
| 只读的代码和数据 | 【开始区域】从hello可执行文件加载进来的程序代码和数据 |

区别举例:连续定义下的地址的紧凑程度
- 操作
- 连续定义了2个整型和2个浮点型2个整型指针,再依次取地址
- Debug下的x86架构指令集
- 取地址:003BF7F4,003BF7E8,003BF7DC,003BF7D0,00A1D020,00A21FB8
- 规律:4字节存储地址,地址递减,整型和浮点型后间隔12个地址,指针地址随机?
- Debug下的x64架构指令集
- 取地址:000000ABD00FFA74,000000ABD00FFA94,000000ABD00FFAB4,000000ABD00FFAD4,000001F1900B10F0,000001F1900B11F0
- 规律:8字节存储地址,地址递增,整型和浮点型后间隔2*16个地址,指针地址随机?
- Release下的x86架构指令集
- 取地址:00DAFEF0,00DAFEEC,00DAFEE8,00DAFEE4,0157DFE0,0157E130
- 规律:4字节存储地址,地址递减,整型和浮点型后间隔4个地址(整型和浮点型均占4字节),指针地址随机?
- Release下的x64架构指令集
- 取地址:00000099000FFAE0,00000099000FFAE4,00000099000FFAE8,00000099000FFAEC,000001FE3EE4F820,000001FE3EE4F7D0
- 规律:8字节存储地址,地址递增,整型和浮点型后间隔4个地址(整型和浮点型均占4字节),指针地址随机?
- 补充
- 好像无论x86还是x64,栈都是往下增长的。方向不同可能是以为编译的缘故???
代码验证
#include <iostream>
using namespace std;
int main()
{
char ac_dog1[] = { "dog" };
char ac_dog2[4] = { "dog" };
char ac_dog3[4] = { 'd','o','g','\0' };
char ac_dog4[4] = { 'c','o' };
char ac_dog5[4] = { 'd','o','g','s' };
char ac_dog6[4];
cout << ac_dog1 << "\t" << &ac_dog1 << endl;
cout << ac_dog2 << "\t" << &ac_dog2 << endl;
cout << ac_dog3 << "\t" << &ac_dog3 << endl;
cout << ac_dog4 << "\t" << &ac_dog4 << endl;
cout << ac_dog5 << "\t" << &ac_dog5 << endl;
cout << ac_dog6 << "\t" << &ac_dog6 << endl;
cout << endl;
cout << &ac_dog4 << endl;
printf("元素\t+法取地址\tASCII\t元素取地址\n");
cout << ac_dog4[0] << "\t"
<< &ac_dog4 + 0 << "\t"
<< int(ac_dog4[0]) << "\t"
<< hex << long(&ac_dog4[0]) << dec << endl;
cout << ac_dog4[1] << "\t"
<< &ac_dog4 + 1 << "\t"
<< int(ac_dog4[1]) << "\t"
<< hex << long(&ac_dog4[1]) << dec << endl;
cout << ac_dog4[2] << "\t"
<< &ac_dog4 + 2 << "\t"
<< int(ac_dog4[2]) << "\t"
<< hex << long(&ac_dog4[2]) << dec << endl;
cout << ac_dog4[3] << "\t"
<< &ac_dog4 + 3 << "\t"
<< int(ac_dog4[3]) << "\t"
<< hex << long(&ac_dog4[3]) << dec << endl;
}
Debug x86模式输出(看来Debug模式才会显示“烫”)
连续定义时地址依次变小
/* 输出
dog 0079FD70
dog 0079FD64
dog 0079FD58
co 0079FD4C
dogs烫烫烫烫co 0079FD40
烫烫烫烫烫烫dogs烫烫烫烫co 0079FD34
元素 +法取地址 ASCII 元素取地址
c 0079FD4C 99 79fd4c
o 0079FD50 111 79fd4d
0079FD54 0 79fd4e
0079FD58 0 79fd4f
*/
Release x86模式输出
连续定义时地址忽大忽小,很奇怪
/* 输出
dog 0053FC18
dog 0053FC1C
dog 0053FC10
co 0053FC08
dogsdog 0053FC14
C 0053FC20
0053FC08
元素 +法取地址 ASCII 元素取地址
c 0053FC08 99 53fc08
o 0053FC0C 111 53fc09
0053FC10 0 53fc0a
0053FC14 0 53fc0b
*/
大端or小端
无论是Debug还是Release,x86还是x64,windows均使用的是小端法
验证代码:
char* p = (char*)&i;
if (*p == 1)
printf("小端模式");
else // (*p == 0)
printf("大端模式");
使用
解决方案资源管理器
结构
- 解决方案(包含n个项目)
- ConsoleApplication(项目名,一个解决方案可以有多个项目)
- 引用
- 外部依赖项
- 头文件(.h)
- 源文件(.cpp)
- 资源文件
- ConsoleApplication(项目名,一个解决方案可以有多个项目)
快捷键
Ctrl+F5,运行
Shift+F9,调试时快速监视
注释快捷键非常诡异
- 注释:ctrl+k+c
- 取消注释:ctrl+k+u