吴恩达深度学习
目录
卷积神经网络(CNN,Convolutional Neural Network)
卷积神经网络的三层
一个典型的卷积神经网络通常有三层
- 卷积层(Conv,Convolution layers),下一节 “单层卷积网络” 中的例子用的就是Conv
- 池化层(POOL,Pooling layers)
- 全连接层(FC,Fully Connected layers)
虽然仅用卷积层也有可能构建出很好的神经网络,但大部分神经望楼架构师依然会添加池化层和全连接层。
幸运的是,池化层和全连接层比卷积层更容易设计。
卷积网络层(Convolutional network layouts)
如何构建卷积神经网络的卷积层?
做法 (单层卷积网络)
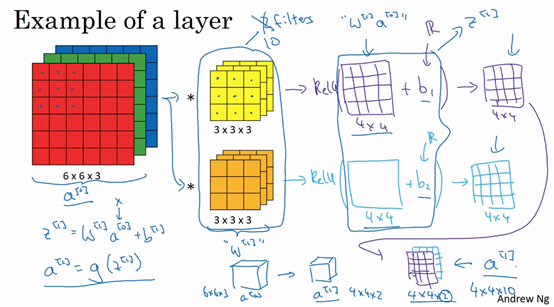
即,我们通过计算将6×6×3的输入变成一个4×4×2的输出
它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
公式 (单层卷积网络)
旧的ReLU神经网络中
a[0]=z[1]=a[1]=xW[1]a[0]+b[1]g(z[1])
在卷积网络层中
过滤器就相当于变量W[1],卷积后的输出就相当于W[1]a[0],所以要还要加一个实数b[1](通过广播加)
a[0]=z(4×4×10)=a[1]=输入(6×6×3)输入(6×6×3)⎩⎨⎧∗ 过滤器1(3×3×3)+b1∗ 过滤器2(3×3×3)+b2⋯,共10个输出(4×4×10)=g(z)=ReLU(z)
为什么卷积能减少特征?
例如:
假设你有10个过滤器,神经网络的一层有10个单元,每个单元3×3×3。那么,这一层有多少个参数呢?
有(3×3×3+1)×10=280个参数
用这10个过滤器来提取特征(如垂直边缘,水平边缘和其它特征)
不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。即使这些图片很大,参数却很少。
不用卷积的话参数随图片大小爆炸级增长
这就是卷积神经网络的一个特征 —— “避免过拟合”
公式 (多层卷积网络)
通用公式
−−−−−−−−−−−−基本filter size 过滤器大小=padding 填充=stride 步幅=过滤器通道数=过滤器数量= −−−−−−−−−−−−尺寸shape(输入)=shape(单个过滤器)=shape(输出)=shape(a[l])=nH/W[l]= −−−−−−−−−−−−梯度样本的数量=shape(输出)=shape(A[l])=shape(权重参数 weights)=shape(权重参数 bias)=参数−−−−−−−−−−−−f[l]p[l]s[l]nc[l−1]nc[l]维度−−−−−−−−−−−−nH[l−1]×nW[l−1]×nc[l−1]f[l]×f[l]×nc[l−1]nH[l]×nW[l]×nc[l]⌊s[l]nH/W[l−1]+2p[l]−f[l]+1⌋下降−−−−−−−−−−−−mm×nH[l]×nW[l]×nc[l]f[l]×f[l]×nc[l−1]×nc[l]1×1×1×nc[l]
补充:
大家看一些资料时时(在线搜索、GitHub上的源代码、一些开源实现、深度学习文献),
会发现关于(高度,宽度,通道)的顺序并没有完全统一的标准卷积
例如有些作者会采用把通道放在首位的编码标准,吴恩达老师则按(高度,宽度,通道损失数量)的顺序。
实际上在某些架构中,会有一个变量或参数来标识计算通道数量和通道损失数量的先后顺序。只要保持一致,这两种卷积标准都可用。
举例 (多层卷积网络)
假设你有一张图片,你想做图片分类或图片识别,把这张图片输入定义为x,然后辨别图片中有没有猫,输出0或1。
我们来构建适用于这项任务的卷积神经网络。针对这个示例,我用了一张比较小的图片,大小是39×39×3,这样设定可以使其中一些数字效果更好。
图像表示

数学表示
−−−−−−−−−−输入层→f[1]=s[1]=p[1]=过滤器数量 nc[1]= 输入,shape(a[0])=shape(a[1])= −−−−−−−−−−第一层→f[2]=s[2]=p[2]=过滤器数量 nc[2]= shape(a[1])=shape(a[2])= −−−−−−−−−−第二层→f[3]=s[3]=p[3]=过滤器数量 nc[3]= shape(a[2])=shape(a[3])= −−−−−−−−−−第三层→shape(a[3])=激活函数=shape(y^)=shape(a[4])= 第一层−−−−−−−−−−310 (Valid卷积)10(nH[0],nW[0],nc[0])=(39,39,3)37×37×10第二层−−−−−−−−−−5202037×37×1017×17×20输出层−−−−−−−−−−5204017×17×207×7×40=1960个特征输出层−−−−−−−−−−将这1960个特征展开成一个向量logistic回归单元或softmax回归单元取决于你要只识别猫还是识别一堆东西7×7×40=1960个特征
注意一个特点:随着神经网络计算深度不断加深
- 图像大小逐渐减小
通常开始时的图像也要更大一些,初始值为39×39,高度和宽度会在一段时间内保持一致
该例子中从39到37,再到17,最后到7 - 通道数量组建增加
该例子中从3到10,再到20,最后到40
在许多其它卷积神经网络中,你也可以看到这种趋势。关于如何确定这些参数,后面章节会更详细讲解
池化层(Pooling layers)
作用:除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性
最大池化(Max pooling)
例子1
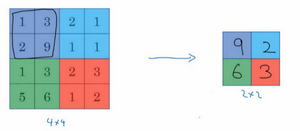
输入是一个4×4矩阵,
用到的池化类型是最大池化(max pooling),执行最大池化的树池是一个2×2矩阵。
执行过程非常简单,把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。
对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
最大池化的输出大小(公式基本同卷积层)
单边输出尺寸=sn+2p−f+1
该例子中
图像
公式
输入尺寸=f=s=p=输出尺寸=4×4220,最大池化一般不用padding2×2
例子2
该例子中
图像
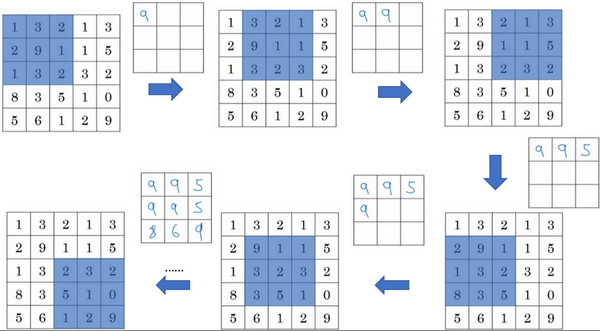
公式
输入尺寸=f=s=p=输出尺寸=5×5210,最大池化一般不用padding3×3
例子3(三维输入)
如果输入是三维的,那么输出也是三维的。例如,输入是5×5×2,那么输出是3×3×2。
如果输入是5×5×nc,输出就是3×3×nc,nc个通道中每个通道都单独执行最大池化计算
理解最大池化
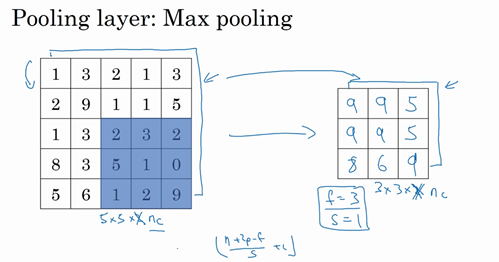
直观理解最大池化:(以例子1为例)
你可以把这个4×4输入看作是某些特征的集合(也许实际上不是),也就是神经网络中某一层的非激活值集合。
数字大意味着可能探测到了某些特定的特征。
比如左上象限具有的特征可能是一个垂直边缘,可能是一只猫眼探测器,可能是是大家害怕遇到的CAP特征。
然而,右上象限并不存在这个特征。
最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。
所以最大化运算的实际作用就是:如果在过滤器中提取到某个特征,那么保留其最大值。
如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小。
(Noter:说白了就是认为数字大的位置是提取到了特征,而数字小的没什么特制,可以被抛弃)
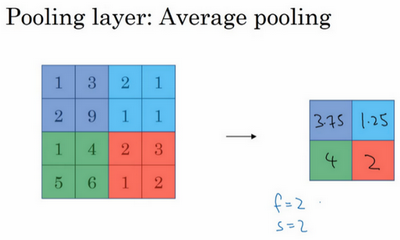
平均池化(Average pooling,没那么常用)
另外还有一种类型的池化,平均池化。
它不太常用。这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值
比较
目前来说,在神经网络中,最大池化比平均池化更常用。
但也有例外,就是深度很深的神经网络。你可以用平均池化来分解规模为7×7×1000的网络的表示层,在整个空间内求平均值,得到1×1×1000
总结
静态属性
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。这点与卷积网络层不同。
实际上,没有什么可以在梯度下降中学习的,一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。
池化的超参数包括过滤器大小f和步幅s
最常用的参数值为f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半(sn+2p−f+1=2n)
也有使用f=3,s=2的情况(输入高宽为奇数时)
至于其它超级参数就要看你用的是最大池化还是平均池化了。
很少使用padding
你也可以根据自己意愿增加表示padding的其他超级参数,虽然很少这么用。
最大池化时,往往很少用到超参数padding。
当然也有例外的情况,我们下周会讲。大部分情况下,最大池化很少用padding。
卷积神经网络示例(仿LeNet-5)
模型搭建
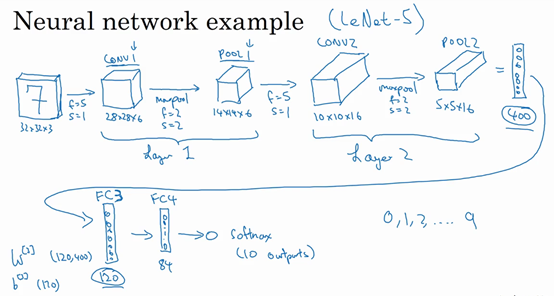
假设,有一张大小为32×32×3的输入图片,这是一张RGB模式的图片,你想做手写体数字识别。
32×32×3的RGB图片中含有某个数字,比如7,你想识别它是从0-9这10个数字中的哪一个,我们构建一个神经网络来实现这个功能。
我用的这个网络模型和经典网络LeNet-5非常相似,灵感也来源于此。
LeNet-5是多年前Yann LeCun创建的,我所采用的模型并不是LeNet-5,但是受它启发,许多参数选择都与LeNet-5相似。
模型的搭建如下图所示
_
32×32×328×28×614×14×610×10×16400=5×5×1612084(识别0∼9数字)10输入层↓ CONV1↓ POOL1↓ CONV2↓ POOL2↓ FC3↓ FC4↓ Softmaxf=5,s=1f=2,s=2f=5,s=1f=2,s=2
_
为什么合并成Layer1?
人们发现在卷积神经网络文献中,卷积有两种分类。
- 一类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的Layer1
- 另一类卷积是把卷积层作为一层,而池化层单独作为一层
虽然你在阅读网络文章或研究报告时,你可能会看到卷积层和池化层各为一层的情况,但这只是两种不同的标记术语
Q:为什么能把他们作为一层?
A:人们在计算神经网络有多少层时,通常只统计具有权重和参数的层,也就是把CONV1和POOL1作为Layer1。
两者都是神经网络Layer1的一部分,POOL1也被划分在Layer1中,因为它没有权重和参数,只有一些超参数
这个例子中,我们
把CONV1和POOL1共同作为一个卷积,并标记为Layer1。
把CONV2和POOL2共同作为一个卷积,并标记为Layer2。
补充
此例中的卷积神经网络很典型,看上去它有很多超参数,关于如何选定这些参数,后面我提供更多建议。
常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,
选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
随着神经网络深度的加深
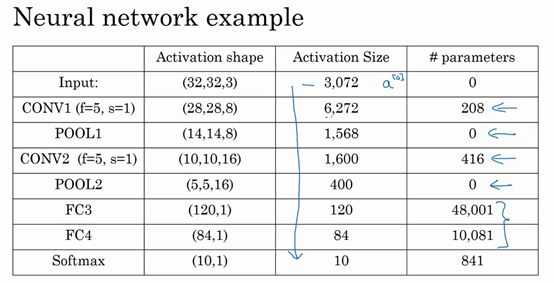
- 高度nH和宽度nW通常都会减少。从32×32到28×28,到14×14,到10×10,再到5×5。
- 而通道数量会增加,从3到6到16不断增加,然后得到一个全连接层。
有几点要注意
- 第一,池化层没有参数
- 第二,卷积层的参数相对较少,其实许多参数都存在于神经网络的全连接层
观察可发现,随着神经网络的加深,激活值尺寸会逐渐变小。如果激活值尺寸下降太快,也会影响神经网络性能。
示例中,激活值尺寸在第一层为6000,然后减少到1600,慢慢减少到84,最后输出softmax结果。
我们发现,许多卷积网络都具有这些属性,模式上也相似。
整合基本模块
神经网络的基本构造模块我们已经讲完了,一个卷积神经网络包括卷积层、池化层和全连接层。
在神经网络中,另一种常见模式就是一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax。这是神经网络的另一种常见模式。
许多计算机视觉研究正在探索如何把这些基本模块整合起来,构建高效的神经网络,整合这些基本模块确实需要深入的理解。
根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例。
下周我会演示一些整合基本模块,成功构建高效神经网络的具体案例。
为什么使用卷积?(Why convolutions?)
卷积层和全连接层相比,有两个主要优势
(这也是卷积网络映射参数少的两个原因)
举例说明一下:
假设有一张32×32×3维度 (3072) 的图片,假设用了6个5×5 (4704) 的过滤器,输出维度为28×28×6。
我们构建一个神经网络,其中一层含有3072个单元,下一层含有4074个单元
- 如果使用全连接
- 两层中的每个神经元彼此相连,然后计算权重矩阵,它等于4074×3072≈1400万,所以要训练的参数很多。
虽然以现在的技术还可以介绍,因为这张32×32×3的图片非常小。但如果这是一张1000×1000的图片,权重矩阵会变得非常大
- 如果使用卷积层
- 一个过滤器有5x5+1=26个参数,一共有6个过滤器。参数共计只有156个。
① 参数共享(Parameter sharing)
观察发现,特征检测(如垂直边缘检测)如果适用于图片的某个区域,那么它也可能适用于图片的其他区域。
也就是说,如果你用一个3×3的过滤器检测垂直边缘,那么图片的左上角区域,以及旁边的各个区域都可以使用这个3×3的过滤器。
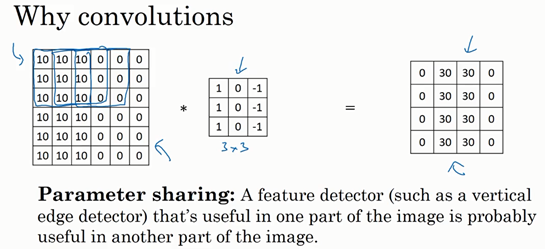
每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其它特征。
它不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征,例如提取脸上的眼睛,猫或者其他特征对象。
即使减少参数个数,这9个参数同样能计算出16个输出。
直观感觉:一个特征检测器,如垂直边缘检测器用于检测图片左上角区域的特征,这个特征很可能也适用于图片的右下角区域。因此在计算图片左上角和右下角区域时,你不需要添加其它特征检测器。
假如有一个这样的数据集,其左上角和右下角可能有不同分布,也有可能稍有不同,但很相似,整张图片共享特征检测器,提取效果也很好。
② 稀疏连接(Sparsity of connections,或叫局部感受)
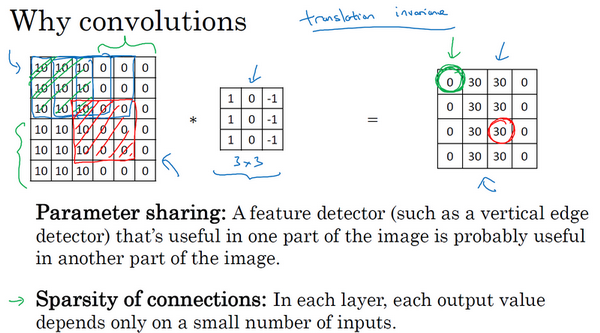
比如,这个绿色标记的0,是通过3×3的卷积计算得到的。它只依赖于这个3×3的输入的单元格,它仅与36个输入特征中9个相连接。
再比如,这个红色标记的元素 30,仅仅依赖于对应的9个特征,其它像素对输出没有任何影响。
而且其它像素值都不会对输出产生任影响,这就是稀疏连接的概念
总结
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防过度拟合。
平移不变:
卷积神经网络善于捕捉平移不变(translation invariance)。比起全连接会更加健壮
通过观察可以发现,向右移动两个像素,图片中的猫依然清晰可见。
神经网络的卷积结构使得即使移动几个像素,依然具有非常相似的特征,应该属于同样的输出标记。