李宏毅机器学习深度学习
目录
分类
(按道理这节的类别有点问题)
对应视频:P22
对应pdf:08_Classification.pdf(06到08跳过了07,07_Batch Normalization.pdf没有对应视频)
先说分类是怎么做的
独热编码(One-hot)
略
Softmax 或 Sigmoid
两个就用Sigmoid,但其实和Softmax是等价的
Softmax:
yi′=∑jexp(yi)exp(yi)
分类问题的Loss
Coss-entropy,交叉熵
Mean Square Error (MSE),Cross-entropy,平方误差信息论里的交叉熵e=e=i∑(y^i−yi′)2−i∑y^ilnyi′
回归函数一般用前者,而分类问题一般用交叉熵
为什么分类问题要用交叉熵比较好
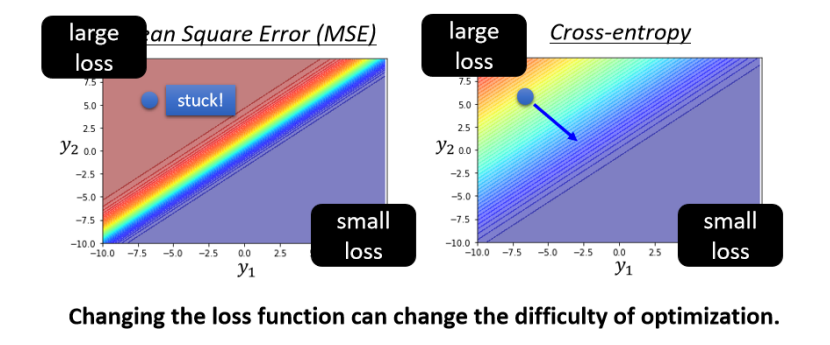
那假设我们开始的地方,都是左上角
如果选择Cross-Entropy
左上角这个地方,它是有斜率的,所以你有办法透过gradient,一路往右 下的地方走,
如果选择Mean square error
你就卡住了,Mean square error在这种Loss很大的地方,它是非 常平坦的,它的gradient是非常小趋近於0的,如果你初始的时候在这个地方,离你的目标非常远,那它 gradient又很小,你就会没有办法用gradient descent,顺利的走到右下角的地方去
2022 - 再探宝可梦、数码宝贝分类器 - 浅谈机器学习原理
如何让理想和现实接近?
(TODO:Understand,这一节不是太明白,还没有pdf可以参考。这章又tm很长,一个多小时,等有时间再重新看一次吧)
h的概念有点难理解
我们希望L(htrain,Dall)和L(hall,Dall)尽可能小 如何让理想和现实接近?什么样的Dtrain可以让理想和现实接近?应该就是在问如何让训练集和测试集更接近后者必定小于前者,但我们希望他两尽可能相似 要满足:L(htrain,Dall)−L(hall,Dall)≤δ只要满足:∀h∈H,∣L(h,Dtrain)−L(h,Dall)∣≤δ/2h是穷举所有可能的数据
还能推得:
L(htrain,Dall)≤L(htrain,Dtrain)+δ≤L(hall,Dtrain)≤L(hall,Dall)+δ/2+δ/2ε=δ/2
证明:
略
例如:
∣H∣Nε∣H∣=10000,N=100, ε=0.1∣H∣=10000,N=500, ε=0.1∣H∣=10000,N=1000,ε=0.1:是:每次随机采样的量:是P(Dtrain is bad)P(Dtrain is bad)P(Dtrain is bad)≤2701≤0.91≤0.00004
经验
我们要比较大的N,比较小的|H|,这样能更好地满足L(htrain,Dall)−L(hall,Dall)≤δ