吴恩达机器学习
吴恩达机器学习
目录
模型评估
模型评估(Evaluating Models)
Debug 机器学习模型
比如拿到一个机器学习模型:
J(\vec w,b)={\color{\orange}\frac{1}{2 m} \sum_{i=1}^{m}\left(f_{\vec w,b}\left(x_{i}\right)-y_{i}\right)^{2}} +{\color{red}\frac\lambda{2m}\sum^n_{j=1}w_j^2}
但它在预测上造成了令人无法接受的巨大错误。你接下来要做什么?
- 获取更多的训练数据 修复高方差
- 尝试使用更少的特征 修复高方差
- 尝试获取附加的特征 修复高偏差
- 尝试加入多项式特征() 修复高偏差
- 尝试增大的值 修复高偏差
- 尝试减少的值 修复高方差
训练集+测试集的方法
通过训练集 (Training Set) 和测试集 (Test Set) 进行模型评估,一般训练集和测试集的比是7:3、8:2
先用训练集数据训练模型,然后用测试集数据来分别计算训练集和测试集的错误率
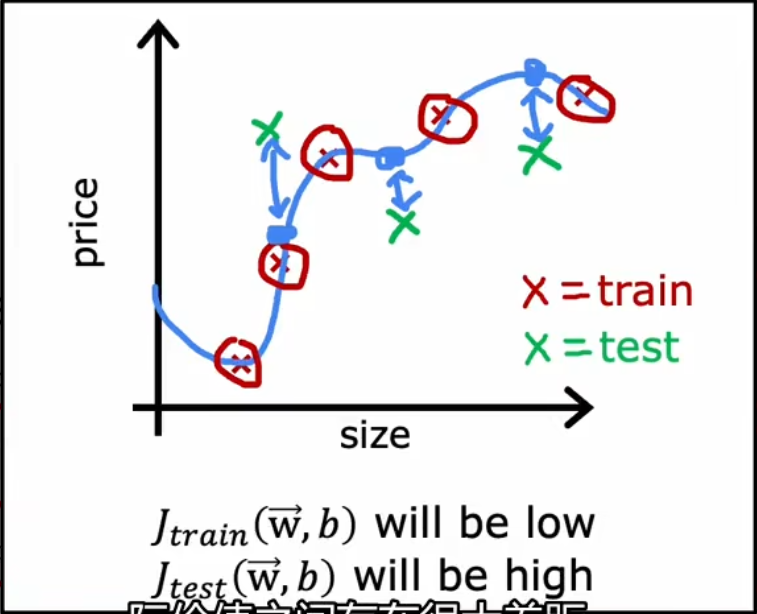
举例 - 线性回归模型
线性回归模型的代价函数和损失计算如下:
如果很低,但是较高,那可能是过拟合程度比较大
举例 - 逻辑回归模型
逻辑回归模型的代价函数和损失计算如下:
(这次我懒得打公式了,直接上图)

交叉验证(Cross Validation)
使用场景的例子:多项式拟合中,如何选择应该用最高幂为多少的模型?
也不能直接比较使用每种幂时的代价,因为这样会容易过拟合

这时可以使用交叉验证(Cross Validation)
方法如下:
① 将数据分成三个部分:
- 训练集(Training Set)
- 交叉验证集(Cross-validation Set),有时也叫 验证集(Validation Set)或 开发集(Development Set / Dev Set)
- 测试集(Test Set)
比例大概分别是60%、20%、20%
② 分别计算他们的损失值:
看起来好像一样,但是功能和作用不同
- Train用于训练多个模型,并交给Vali来选择最好的一个
- Vali用于选择模型
- Test用于检查模型的泛化能力
③ 最后根据计算结果来选择模型就行
偏差、方差(Bias & Variance)
通过交叉验证判断高方差和高偏差
偏差 (Bias) 与方差 (Variance) 进行诊断(Diagnose)
复习一下(“过拟合问题” 一章)
若拟合过低:我们称为 欠拟合(Underfit),也可以用另一个术语描述: 高偏差(High Bias)
例如你通常不能用一个线性回归模型或二阶多项式回归来拟合一个多项式回归模型
若拟合过高:我们称为 过拟合(Overfit),也可以用另一个术语描述:高方差(High Variance)
或者称为 有泛化误差(Generalization Error)例如你通常不能用一个非常高阶的多项式回归模型来拟合数据
诊断方式
高方差时 高 高 高偏差时 很低 很高 恰到好处 低 低 高方差且高偏差 高 高
建立性能评估基准(Establishing a baseline level of performance)
如何判断算法是否具有高偏差或高方差?
一般来训练误差是否远高于人类水平
比如在一个语音识别中:
前两个比较可以得知模型是否高方差,后两个比较可以得知模型是否高偏差
你希望能到达的错误级别是多少?
- Human level performance,人的水平表现
- Competing algorithms performance,竞争算法性能
- Guess based on experience,基于经验的猜测
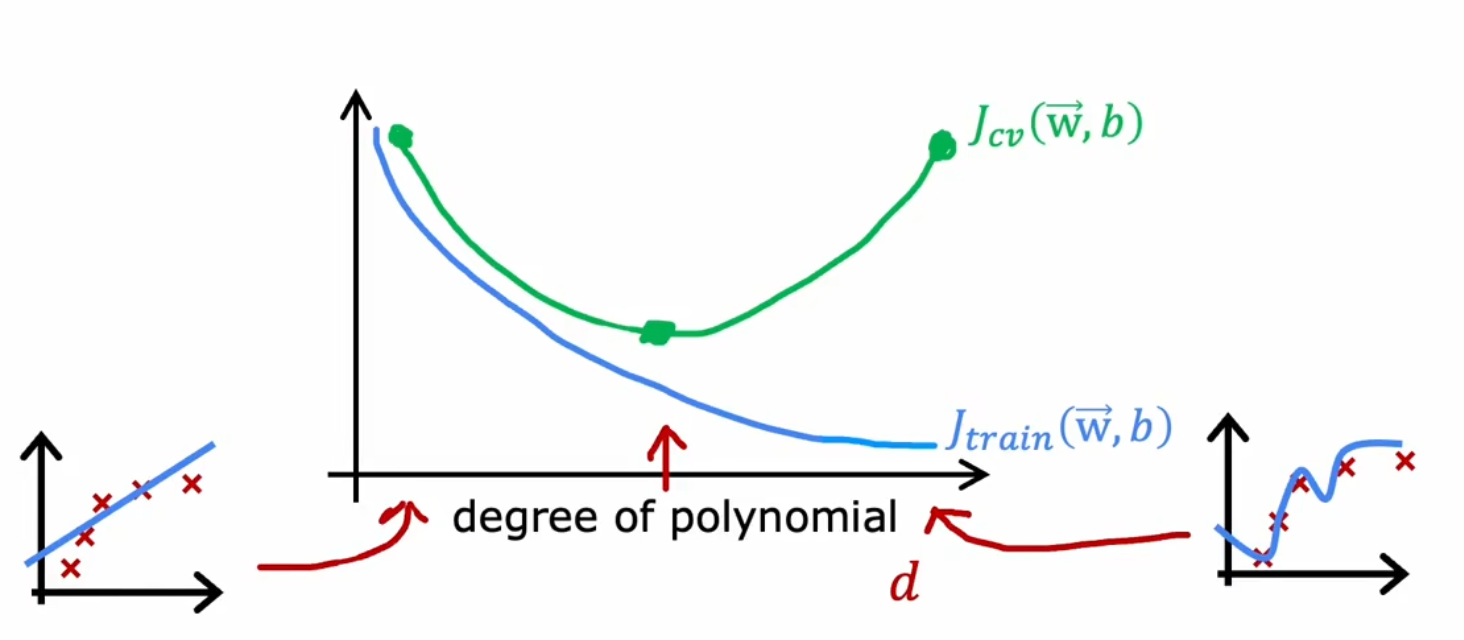
误差图
Choice 多项式次数 / 模型
图解
- 纵轴为误差,横轴为多项式次数 / 模型复杂度
- 左侧(多项式次数低),模型高方差高偏差
- 右侧(多项式次数高),模型低方差高偏差
- 我们应该找到一个平衡点,使和都尽量低
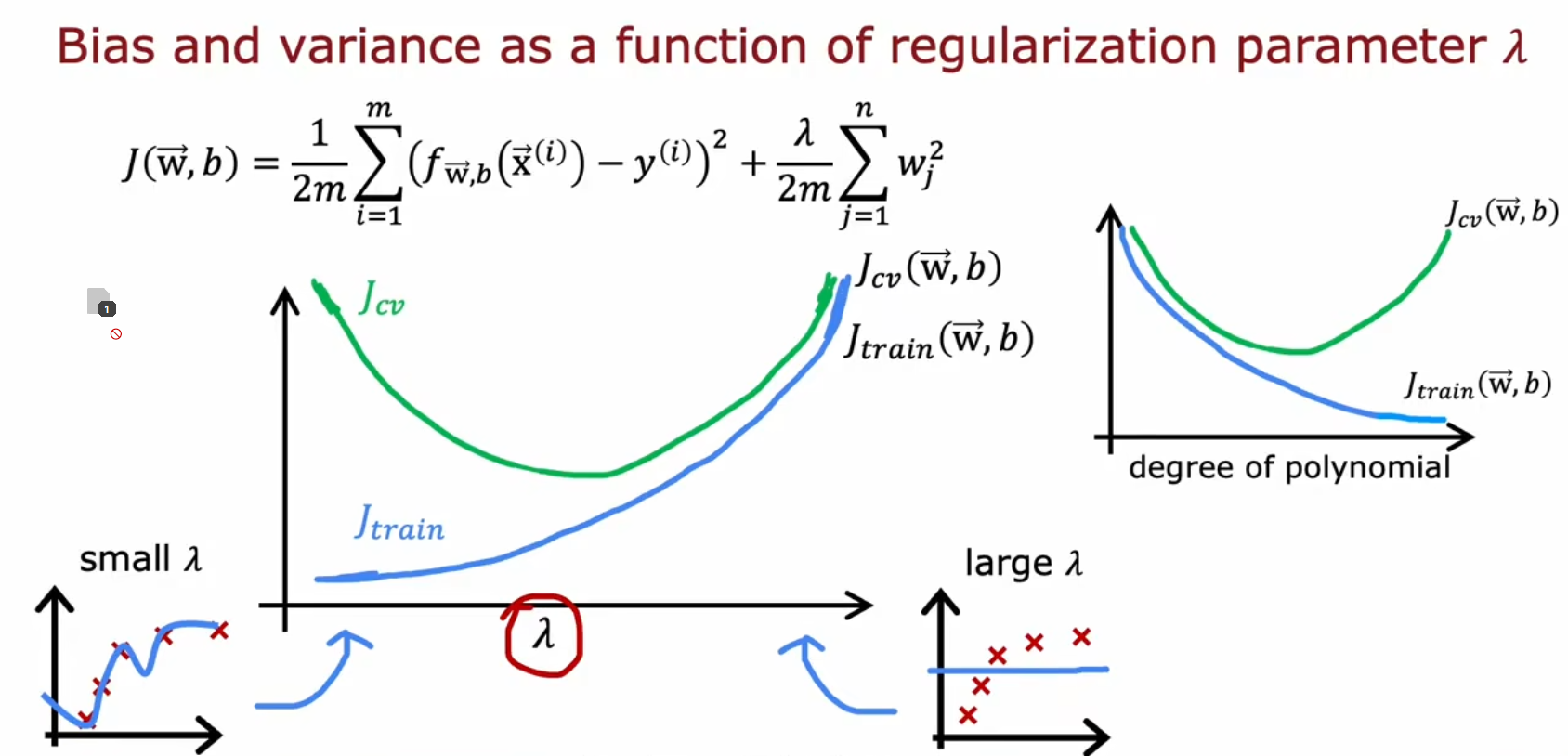
Choice 正则化参数
正则化可以减少模型偏差。
以线性回归为例
- 如果变大,则曲线的变化成都会变低
- 如果超级大,则曲线会变成一条平行于x轴的线。
- 如果为零,则正则化不起作用,等于没有正则化
图解
- 纵轴为误差,横轴为正则化参数
- 左侧,模型低方差高偏差
- 右侧,模型高方差高偏差
- 我们应该找到一个平衡点,使和都尽量低
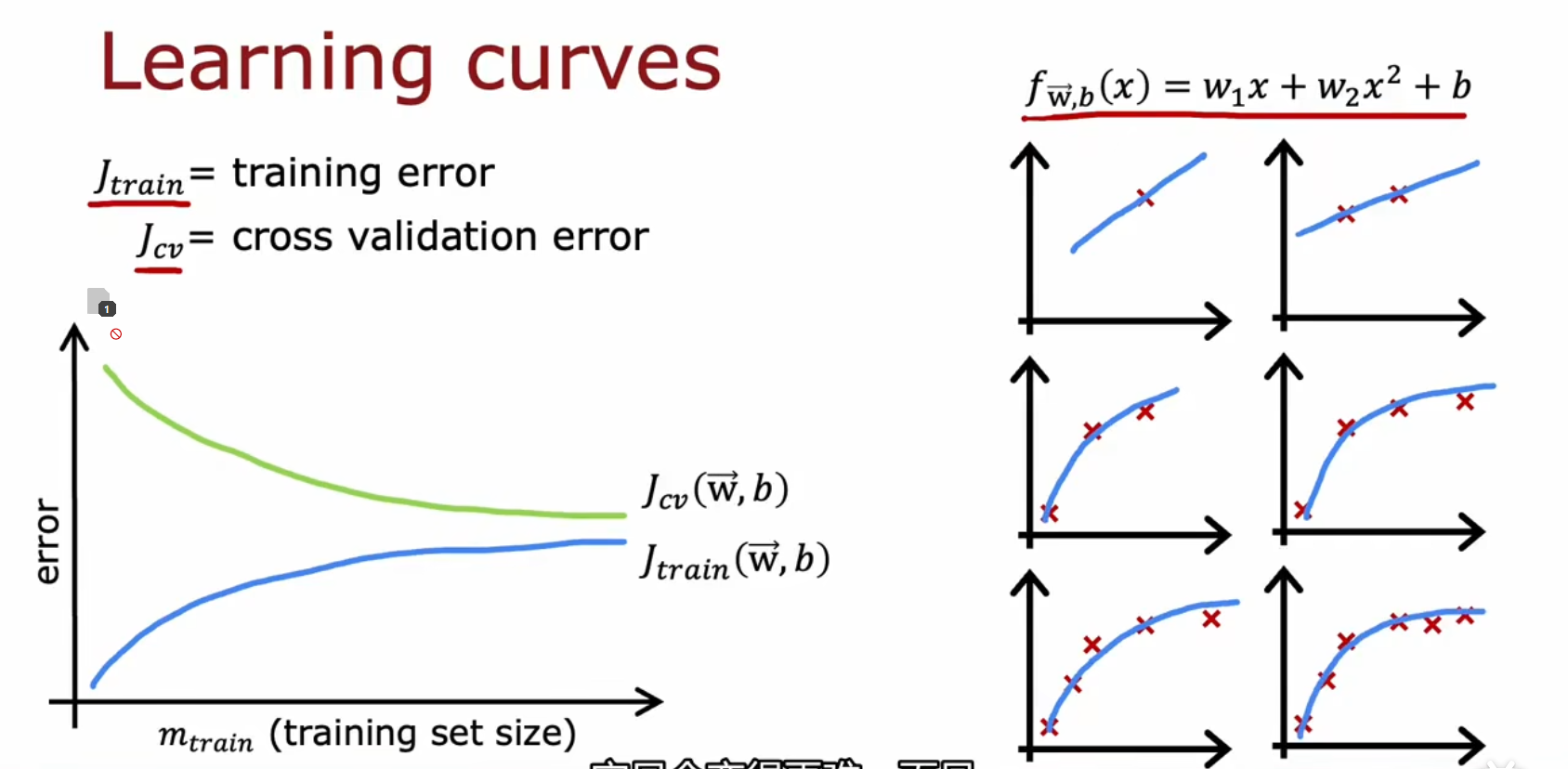
Increase 训练量 / 学习曲线
图解
- 纵轴为误差,横轴为模型的训练量。这种图也叫做学习曲线
- 左侧,模型低方差高偏差
- 右侧,模型低方差低偏差
- 训练量越多越好。特别对于高方差的情况,训练量的增大改善比较明显
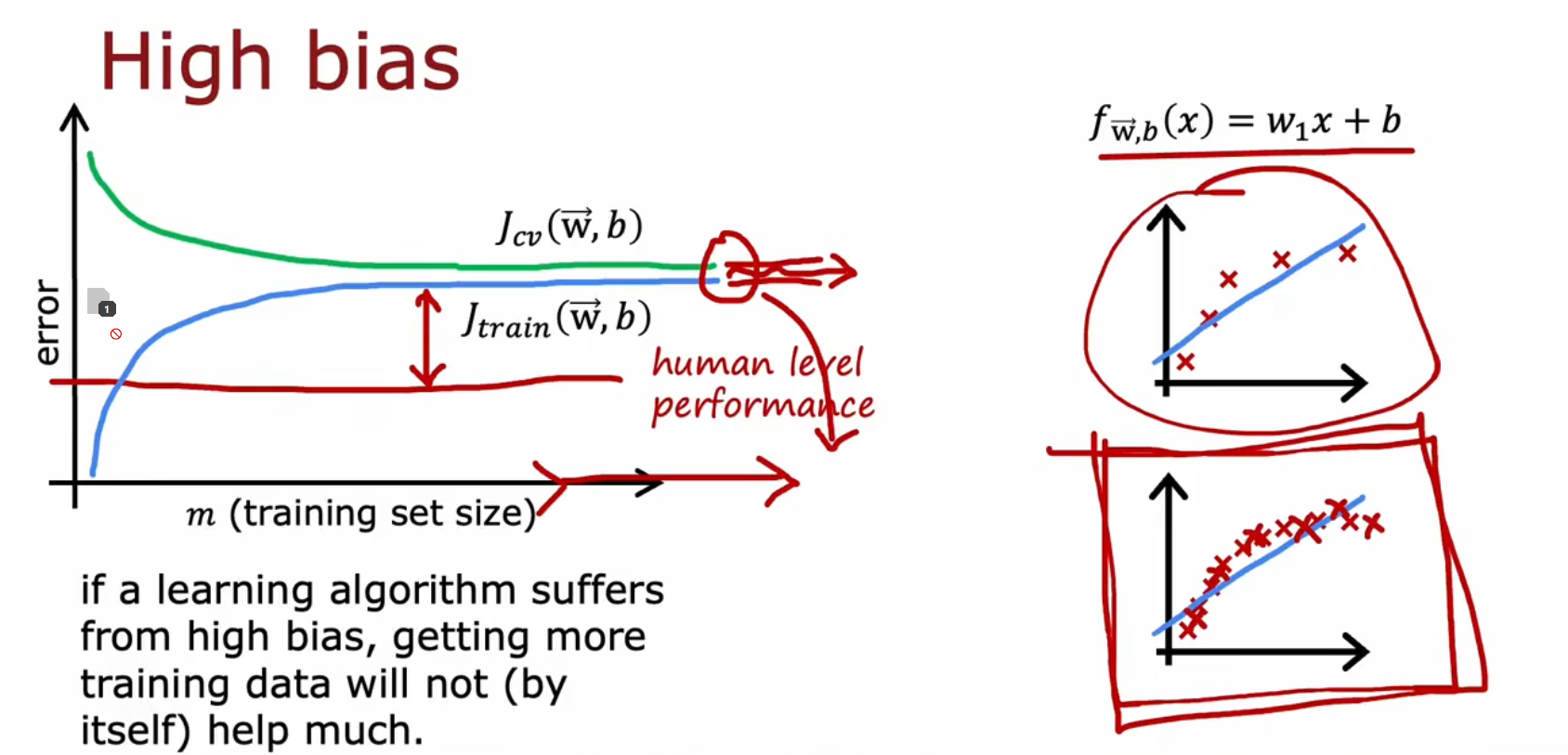
高偏差时
增大训练样本虽然是更好的,不一定能有效解决高偏差问题
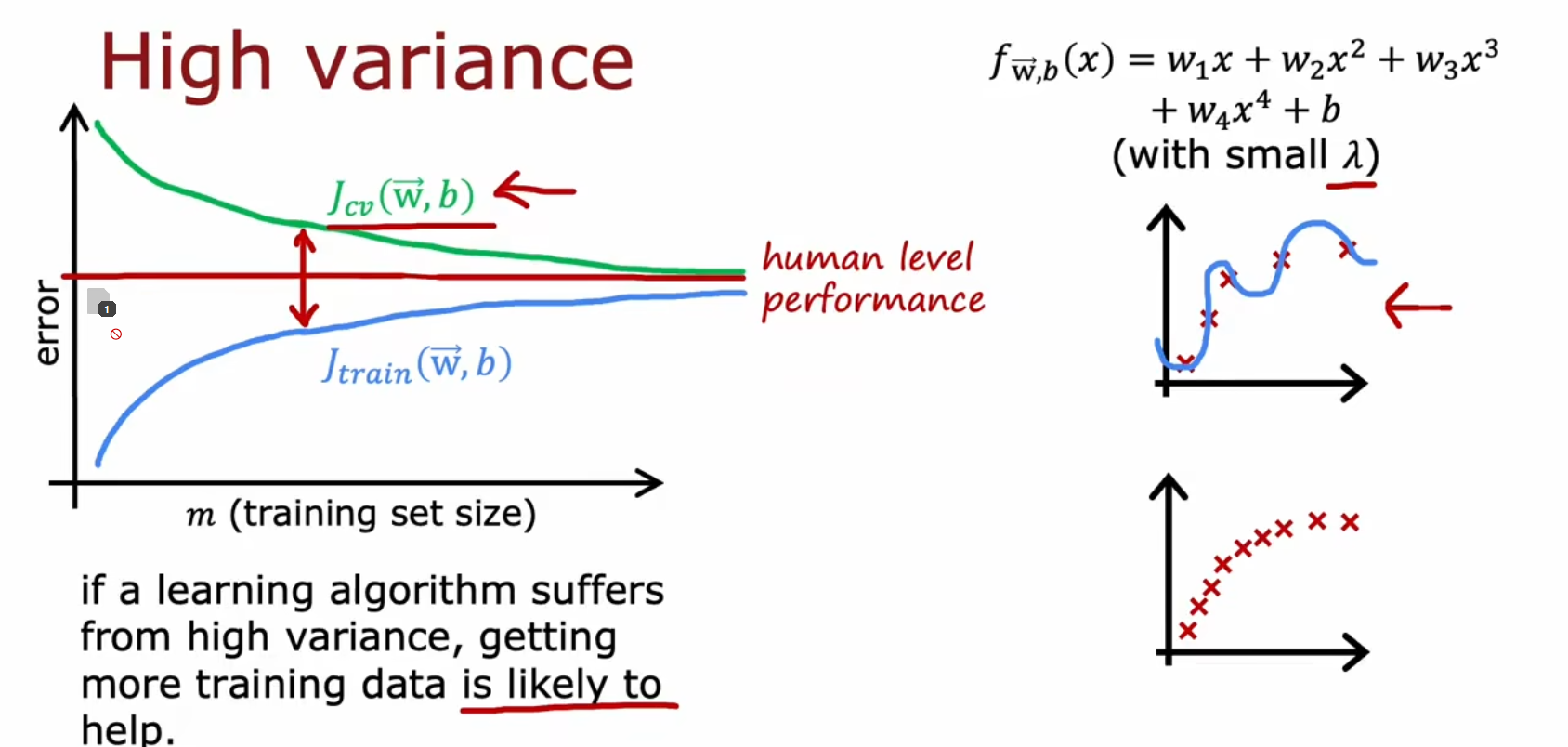
高方差时
增大训练样本能有效解决高方差问题
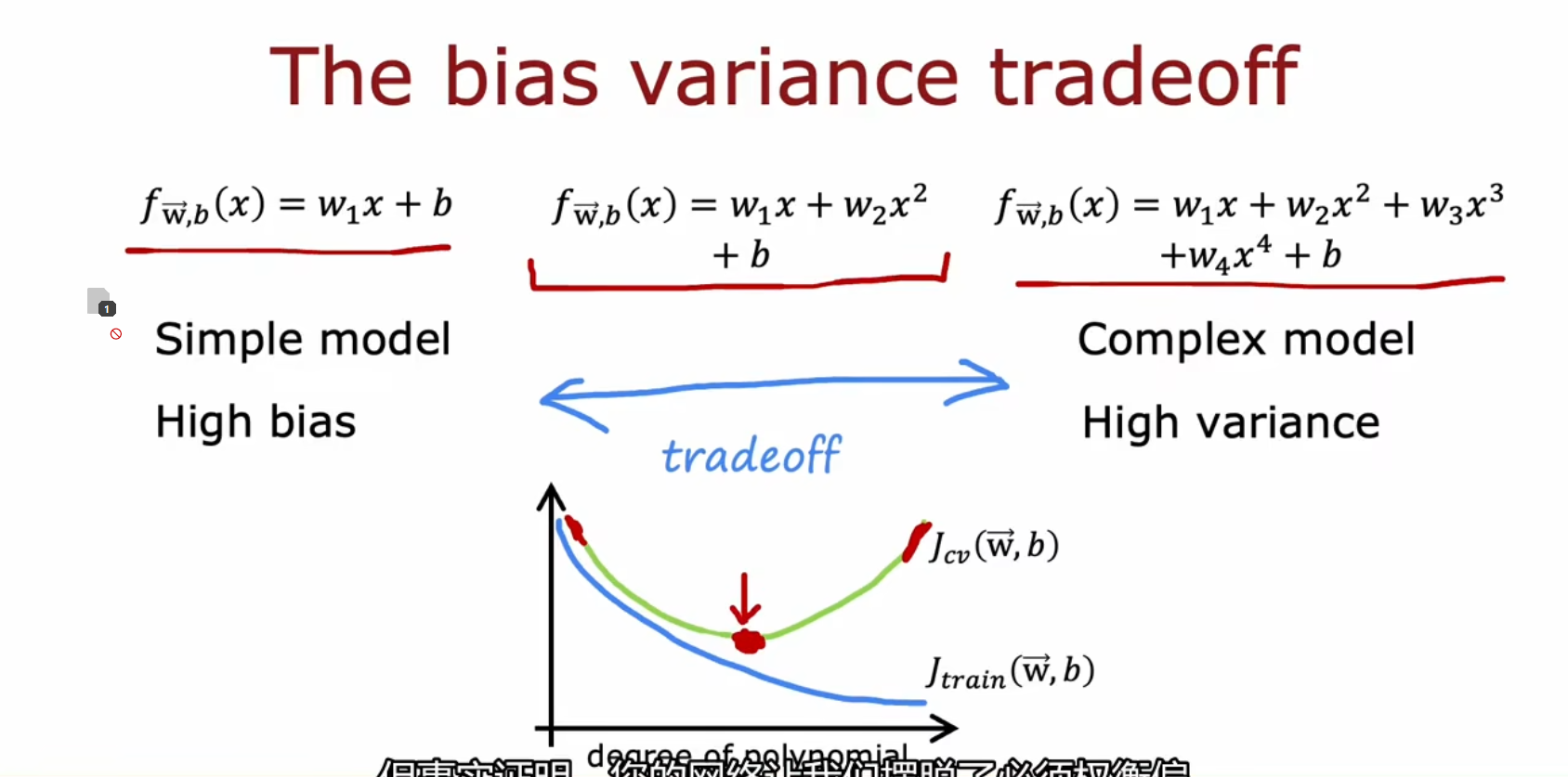
大数据方法
高方差和高偏差都是不好,往往我们需要在他们之间进行权衡(Tradeoff)
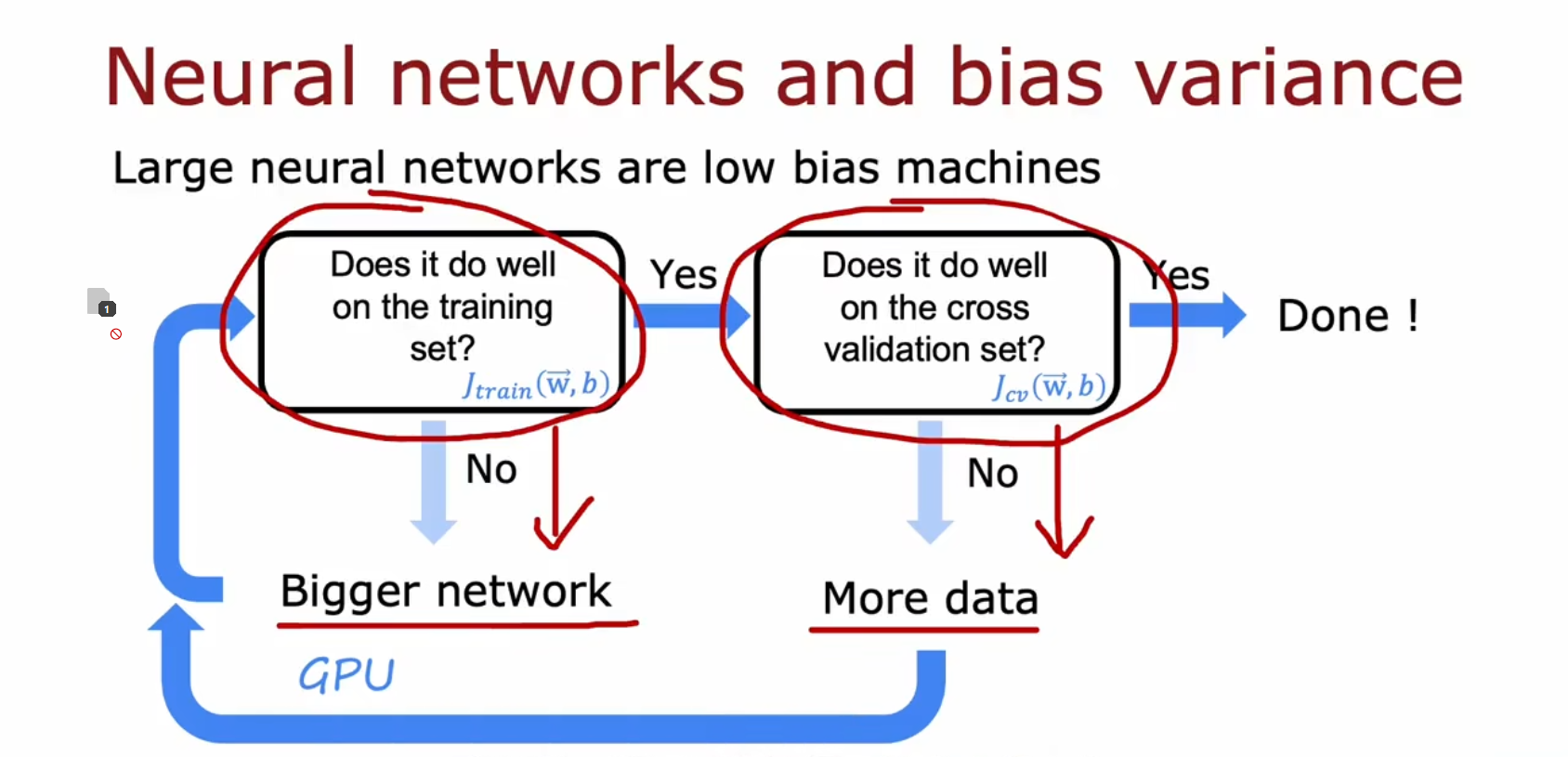
而大数据提供了一种解决高偏差和高方差的新方法 —— 构建大型神经网络
只要选择适当的正则化方法,大型神经网络通常会做得更好或更好。缺点就是训练会变得更慢
代码
model = Sequential([
tf.keras.layers.Dense(units=25, activation='relu', kernel_regularizer=L2(0.02))
tf.keras.layers.Dense(units=15, activation='relu', kernel_regularizer=L2(0.02))
tf.keras.layers.Dense(units=10, activation='sigmoid', kernel_regularizer=L2(0.02))
])误差分析(Error Analysis)
对于提高学习算法性能,偏差和方差是最重要的想法,那么误差分析可能排第二
比如:
在一个垃圾邮箱分类器中。500个交叉验证示例中,算法错误地分类了其中100个。
那么我们需要手动地去检查这100个例子,并根据相同的特征对他们进行分类并统计
造成分类错误 可能的原因有:
- 医药广告?
- 故意拼写错误(w4tch,med1cines)(这也是为什么我经常会接收到一些没有被屏蔽的垃圾短信中,常用错别字和简字)
- 网络钓鱼、窃取密码
- 嵌入图像中的垃圾邮件(那么仅通过关键字无法判断是否是广告)
比如分类后他们的数量分别是21、3、7、18、5个
这些分类是不互斥的,比如一个没被过滤的垃圾邮件可能即有拼写错误,也有网络钓鱼的内容
有些误差分析是比较难的。比如预测一个人是否会对某类广告感兴趣而去点它,如果判断错了,那我怎么知道他为什么不去点
精确率、召回率(Precision & Recall)
情景 - 倾斜数据集的误差指标(Skewed data set ...)
情景:
例如你了一个二元分类器来检测一种罕见病,1为患病,0为不患病
机器学习预测的准确率达到了99%,看起来不错。
但是!如果这是一种罕见病,本身出现的几率就非常低,加入出现概率是0.5%
这时,哪怕模型输出恒为0,准确率也能达到99.5%。这比你的机器学习准确率还高
启示:
如果你有一给罕见类(Rare Class)
分类中几种算法分别可以达到99.5% 99.2% 99.6%准确度,其实你很难知道哪种算法是最好的算法
你需要查看精确率和召回率(Precision、Recall)并确保这两个值都相当高
定义精确率与召回率
定义以下四种情况
实际为1 实际为0 预测为1 正确肯定 / 真阳性(True Positive) 错误肯定 / 假阳性(False Positive) 预测为0 错误否定 / 假阴性(False Negative) 正确否定 / 真阴性(True Negative)
(补充:假阴性也叫伪阴性、负误识,其概率也叫漏报率)
定义精确率和召回率
精确率(Precision)
大概含义:我初步诊断说你可能有癌症阳性,你可以做好心理准备,但不需要太绝望,我们需要更详细的诊断来看是否是误诊了。
你该庆幸我们的精确率只有75%,你还有25%的可能是假阳性。
当然精确率越高越好,免得假阳性的病人白白担惊受怕。召回率(Recall):
大概含义:假设召回率是95%。那么如果你有病,有95%可能我们能判断出来。
但也不是我们说你没病你就一定没病了,你有可能是那5%的被漏报的
召回率还尽可能高,漏报率要尽可能低漏报率(False negatives)
大概含义:你有病但我没诊断出来,漏报了。病情没有及时发现,没有及时得到治疗,这病人也太惨了。
召回率还尽可能高,漏报率要尽可能低
应用举例
假设倾斜数据集模型的实际情况和预测情况如下:
机器学习预测的情况
实际为1 实际为0 总和 预测为1 15例 5例 20例 预测为0 10例 70例 80例 总和 25例 75例 100例
- ,
直接令的情况
实际为1 实际为0 总和 预测为1 0例 0例 00例 预测为0 25例 75例 100例 总和 25例 75例 100例
- ,
让你预测谁有罕见病,你就说谁都没有是吧
一般来说精确率或召回率为0的算法,是没有用的
直接令的情况
实际为1 实际为0 总和 预测为1 25例 75例 100例 预测为0 0例 0例 00例 总和 25例 75例 100例
- ,
让你预测谁有罕见病,你就说谁都有是吧
权衡(Trading off)、F1分数
- 高精确率意味着:判断患者患有这种罕见病时,患者可能拥有这个病,这是一个准确的诊断
- 高召回率意味着:如果有患者患有罕见病,大概率能被检测得出来
- 准确率和召回率都应该尽量地高,但有时他们是互斥的
- 高召回率:需要宁杀错勿放过,会导致准确率减低
- 高准确率:意味着如果你患病的潜在风险不是太高的话,我就当你不患病了。会导致召回率降低
- 我们需要在召回率和准确率之间作出权衡
设置一个阈值
理念是,每当我们预测患者患有疾病时,
如果该疾病,即使不积极治疗,后果也不是那么严重,则阈值升高。
如果该疾病,倘若不积极治疗,后果会非常非常严重,则阈值降低。
阈值升高,会导致高准确率,低召回率。
阈值降低,会导致低准确率,高召回率。
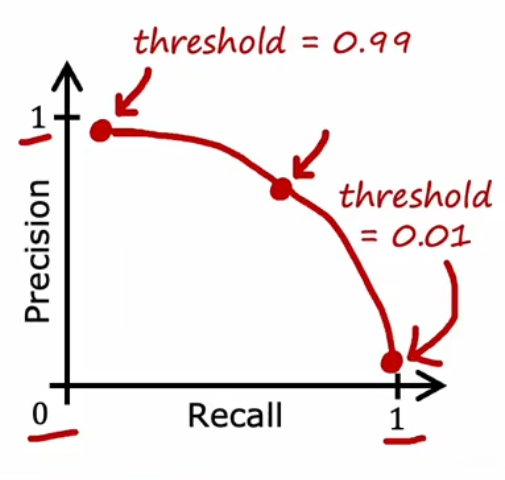
还有个指标叫做 "F1 Score",有时用于选择最佳的权衡
| 精确率 Precision (P) | 召回率 Recall (R) | F1分数 Score | ||
|---|---|---|---|---|
| 算法 1 | 0.5 | 0.4 | 0.444 | |
| 算法 2 | 0.7 | 0.1 | 0.175 | |
| 算法 3 (输出1) | 0.02 | 1.0 | 0.0392 |
用什么方法来评价呢?
平均值:不要用,这里的第三项恒输出1,分数却最高,明显不合适F1分数:更关注较低的分数,页脚调和平均值
机器学习开发的迭代
机器学习的迭代循环(Iterative loop of ML development)
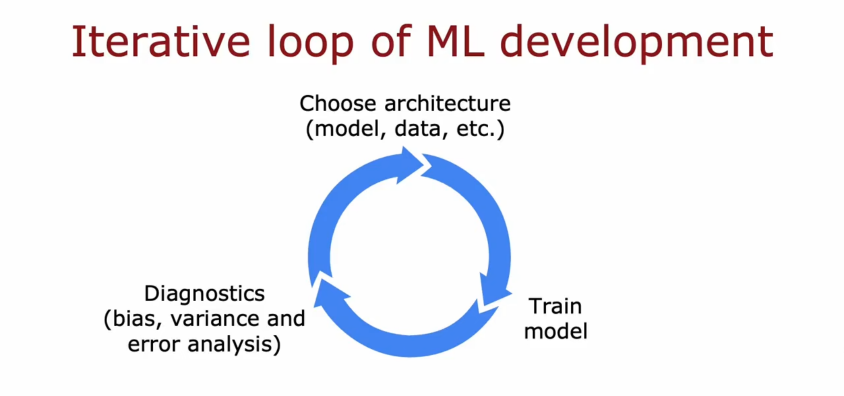
- 选择结构(模型、数据等)
- 训练模型
- 诊断(偏差、方差、误差分析,另外存在罕见类时还要看精确率和召回率)