吴恩达机器学习
吴恩达机器学习
目录
第三课导读
无监督学习(Unsupervised Learning)
- 聚类(Clustering)
- 异常检测(Anomaly detection)
推荐系统(Recommender Systems)
强化学习(Reinforcement Learning)
聚类(Clustering)
概念
什么是聚类?比如无监督学习的二元分类
应用举例:
- 分组相似的新闻
- 市场划分
- DNA 分析(哪些片段决定一个特性)
- 天文数据分析(哪些是一个星系的)
K-means
K-means 直观理解
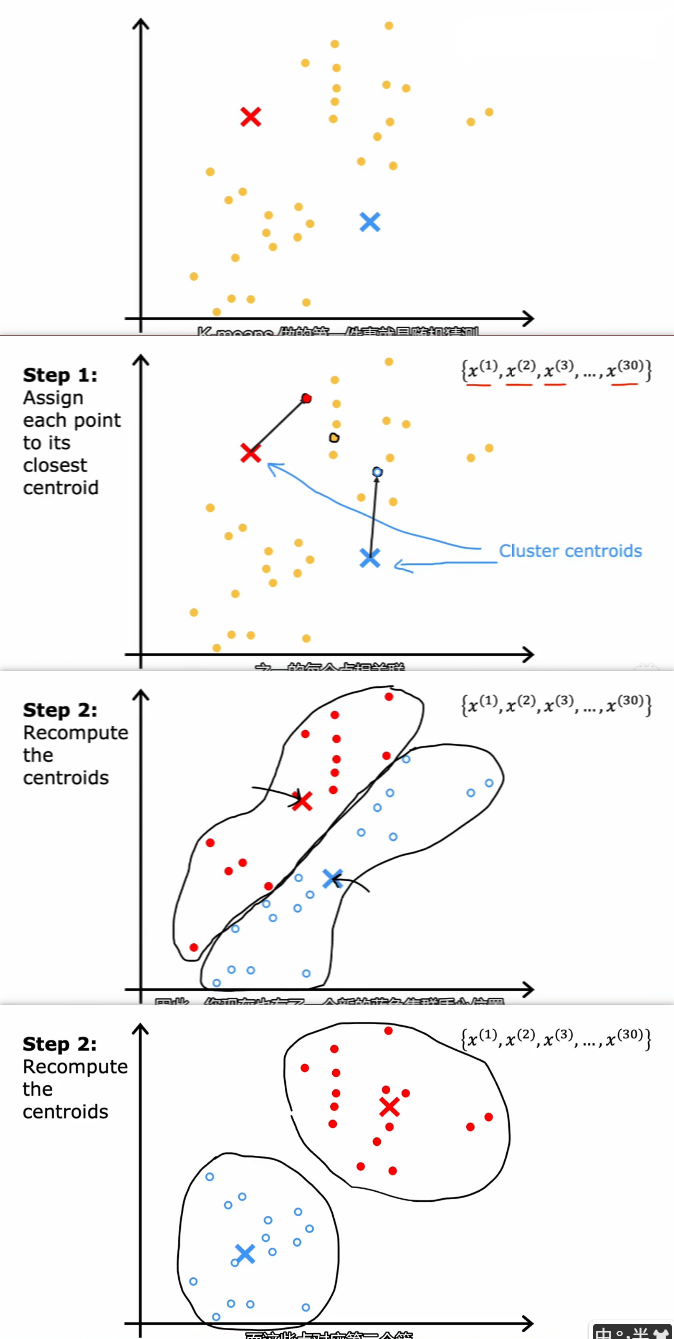
步骤:
- 第一件事就是随机猜测,集群的重心在哪。给出两个点
其中聚类的中心称为 聚类中心(Cluster centroids) - ① 将每个点分配到其最近的聚类重心上
- ② 重新计算质心。比如查看红点并取平均值(取质心),然后将红色的聚类中心移到该质心上
- 迭代上面两步,直到聚类重心的位置收敛
图示:
K-means 算法补充
- 随机初始化K个聚类质心(前面的例子是两个,但可以有多个,K<m即可),
- 重复以下直到收敛
- 将每个点分配到最近的聚类中心
- 调整聚类中心的位置为
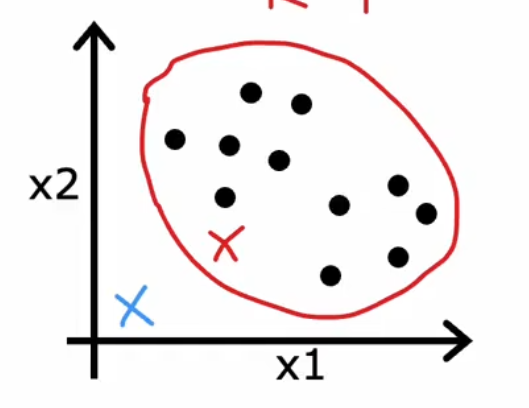
注意一种特殊情况:如果一开始,有一个聚类中心一个点都没被分配到,那么要重新随机分配
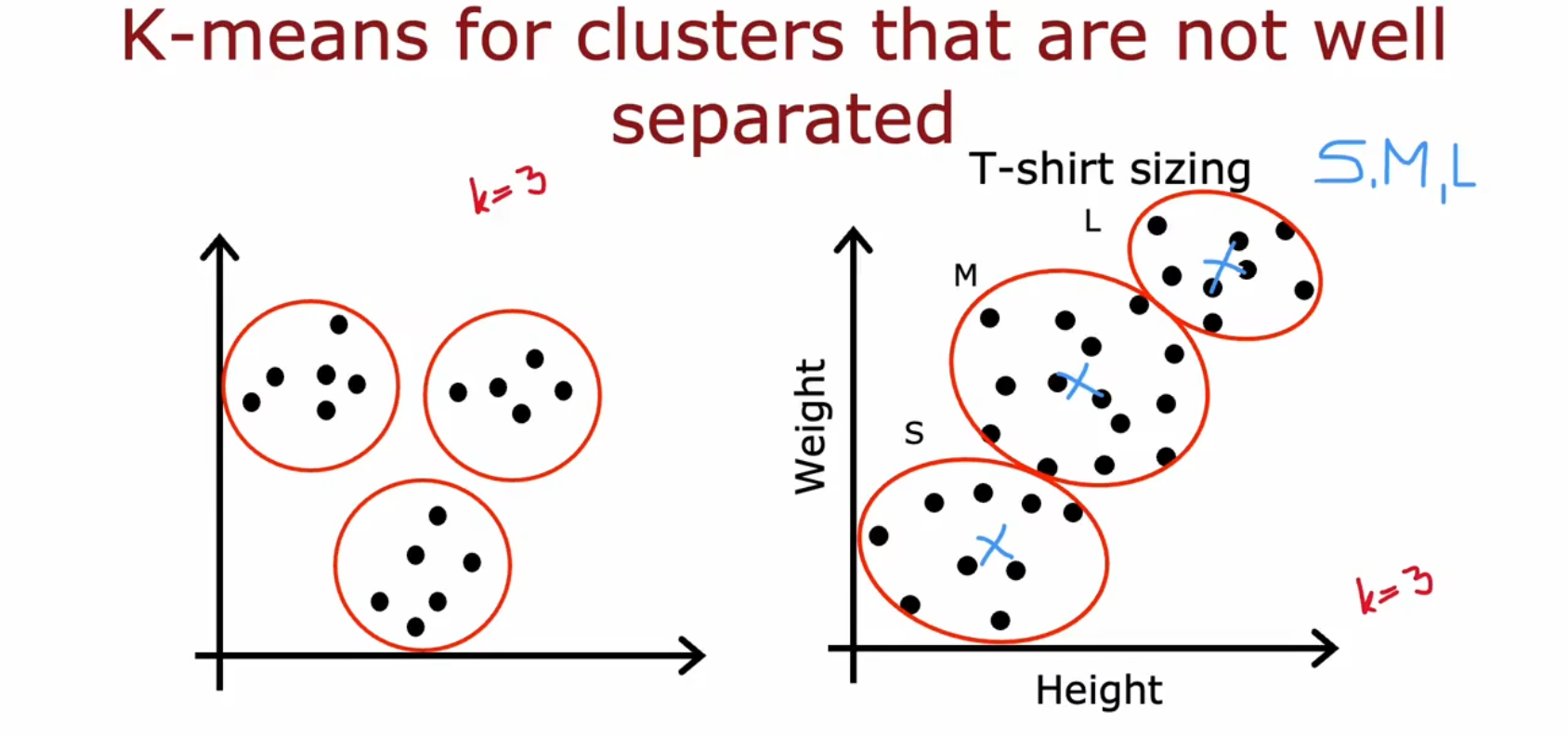
对于没有很好集群离散的数据也适用
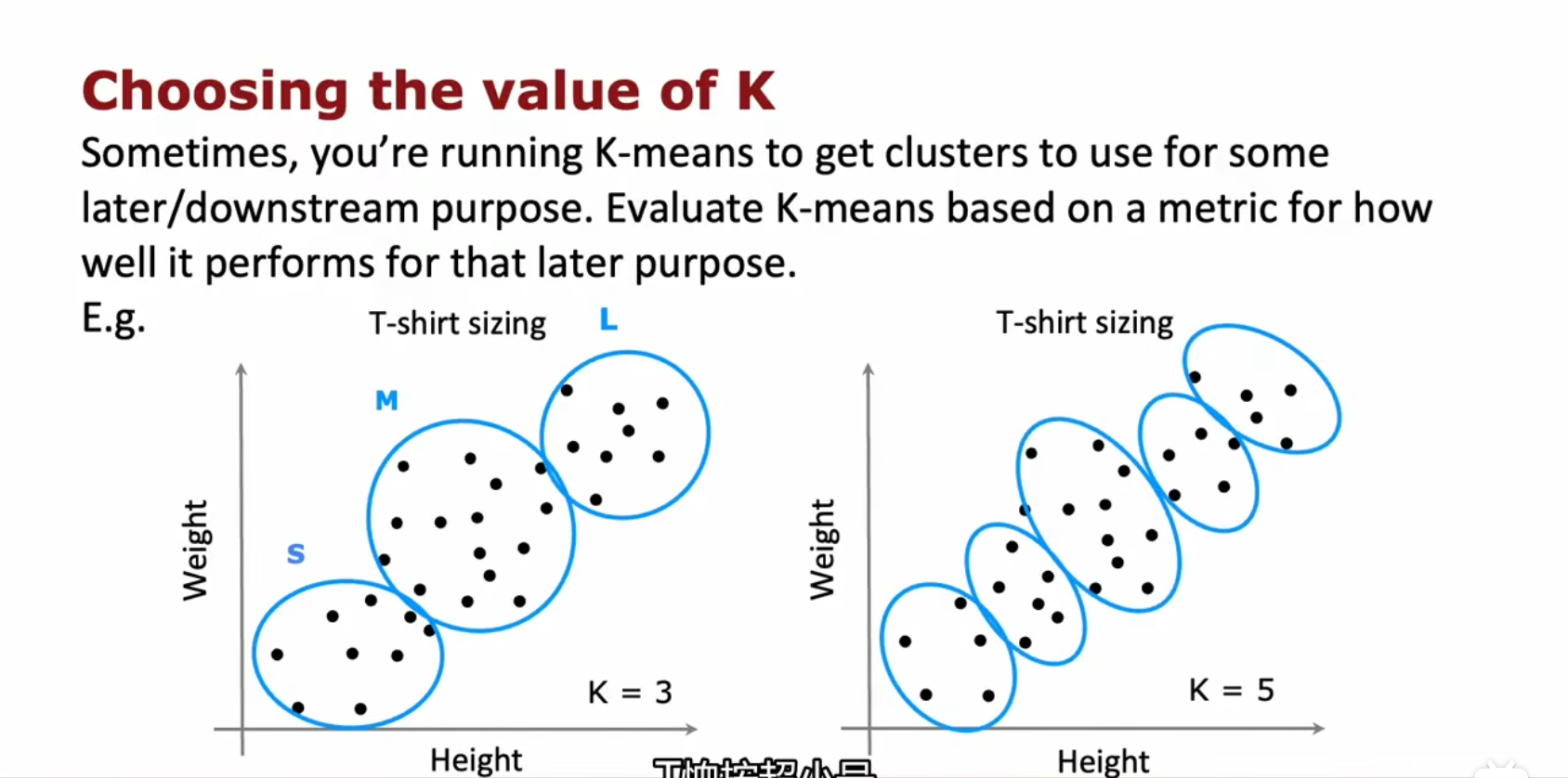
比如根据体重和高度来分类T-shirt的size(S,M,L码)
K-means 成本函数优化
优化目标(Optimization objective)
先定义一些符号
成本函数
这个成本函数在文献中也叫 失真函数(Distortion function)
通过成本函数,我们可以更好地去移动聚类中心。
而不是只移动到质点处或平均值处,那样的话损失函数是不加平方的,
K-means 初始化(Random initialization)
第一步是随机猜测的聚类中心,但是怎么进行随机猜测?(除了 “随机”,还有 “猜”)
如果初始位置不好,可能会导致最后聚类的结果较差
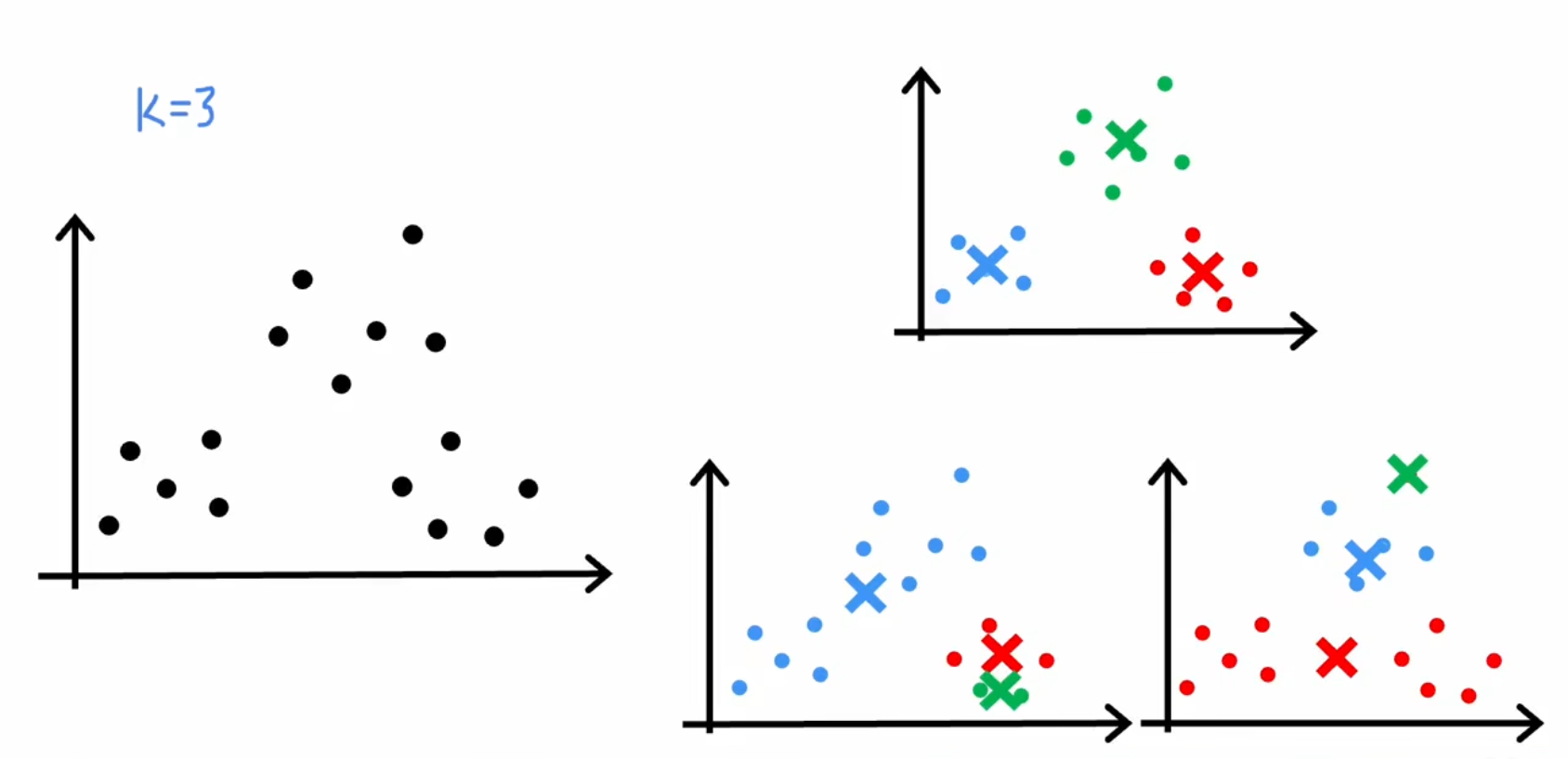
方案是多次随机初始化点,最后的成本函数收敛值可能不同,使用成本最低的那个方案
一般可以随机初始化聚类中心50~1000次
选择聚类数量
之前都是要手动选择聚类数量(K的值),那么
- 有没有方法让程序自己判断聚类数量呢?
- 用什么方法可以衡量哪种聚类数量是更好的呢?直接用成本函数不行,一般聚类数量越多损失越少
多个可行K值
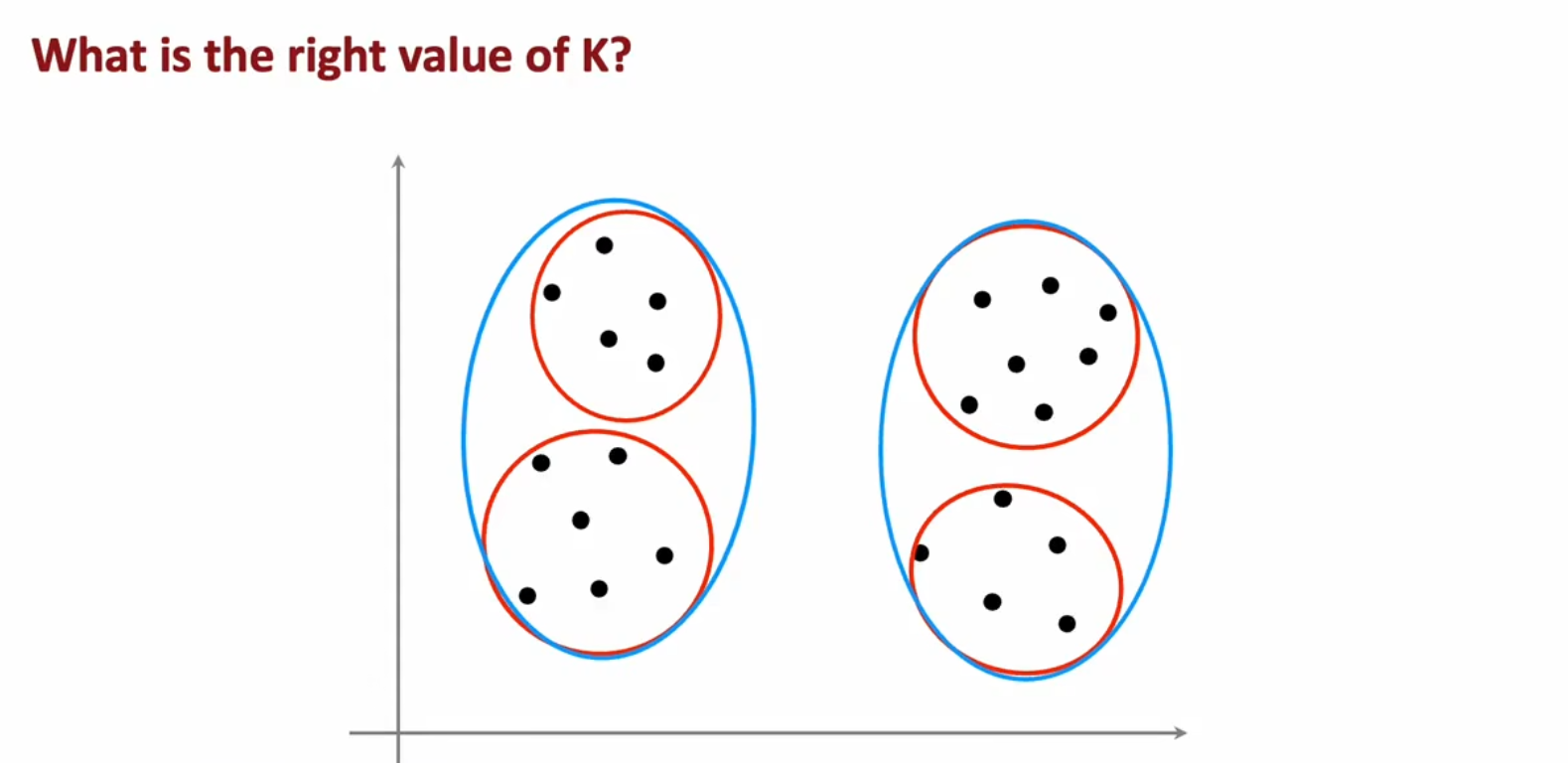
有时候,K的值是任意一点的
比如下面两种K值都是可行的
比如根据体重和身高来分类 T-shirt 的型号,设置K=3或5或其他都是可以的
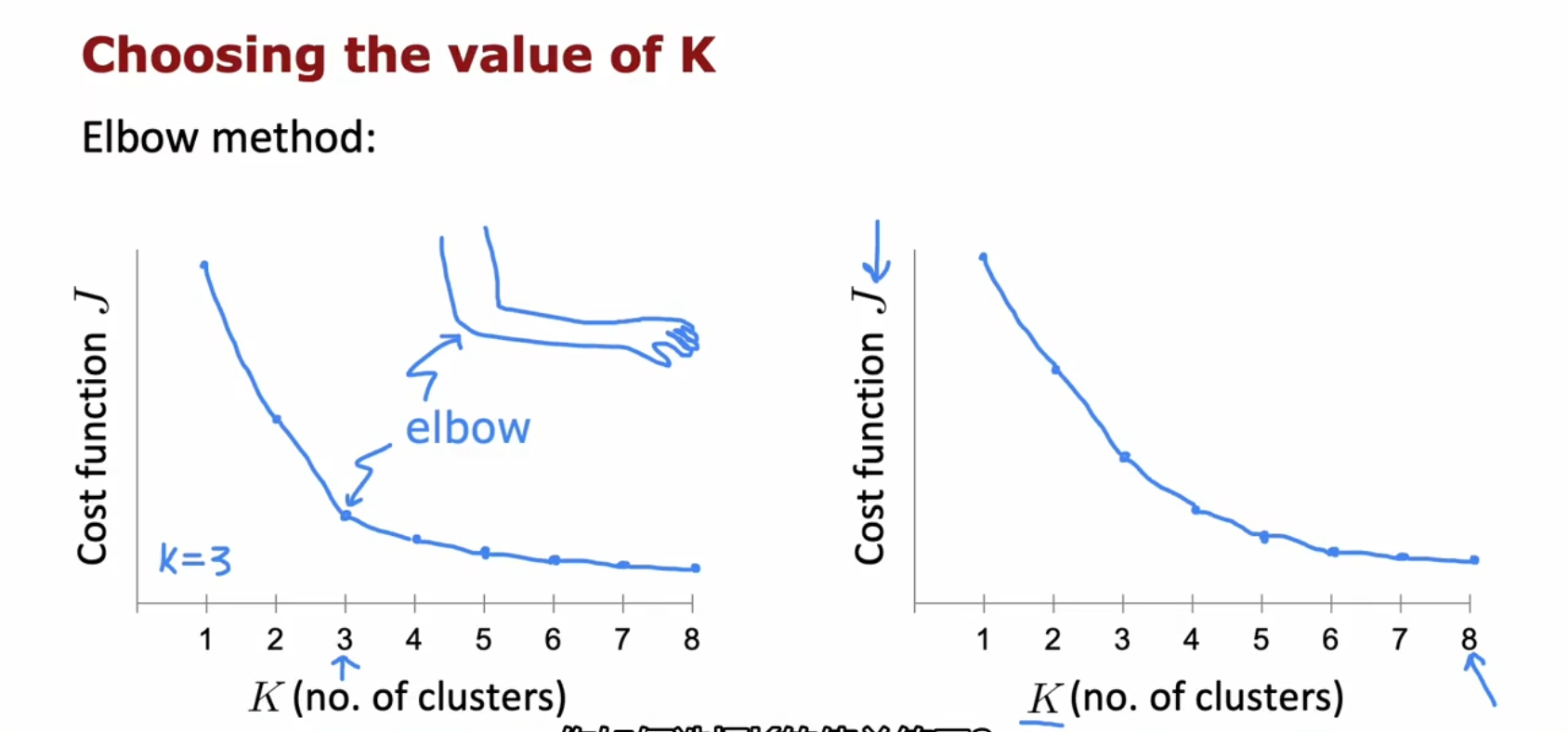
肘法(Elbow method)
(吴恩达老师说他自己不使用这种方法,应该是不好用,这里仅供参考)
就是绘制 K-J 图像,然后找到像肘部的位置去选择。缺点是如果该图像过度很平稳,很难找到一个 “明确的肘部”
其他方法
[【CSDN】转-机器学习之确定最佳聚类数目的10种方法](https://blog.csdn.net/qq_43240060/article/details/105609714)