吴恩达机器学习
目录
异常检测(Anomaly detection)
应用:发现异常事件,比如:
- 欺诈检测(fraud detection)。
x(i)是用户的活动 - 监视数据中心中的计算机。
x(i)是机器的特征,分别是内存占用、硬盘数、CPU负载、网络流量 - ……
原理
例子:用异常检测来查看正在制造的飞机发动机,可能存在的问题
飞机发动机的特征:x1=生成热量x2=震动幅度⋯ 训练集:新发动机:{x(1),x(2),⋯,x(m)}xtest 目标:看这台新的发动机和以前制造的发动机相似程度,并给出相似概率。若概率p(xtest)<ε,则判断有异常若概率p(xtest)≥ε,则判断无异常

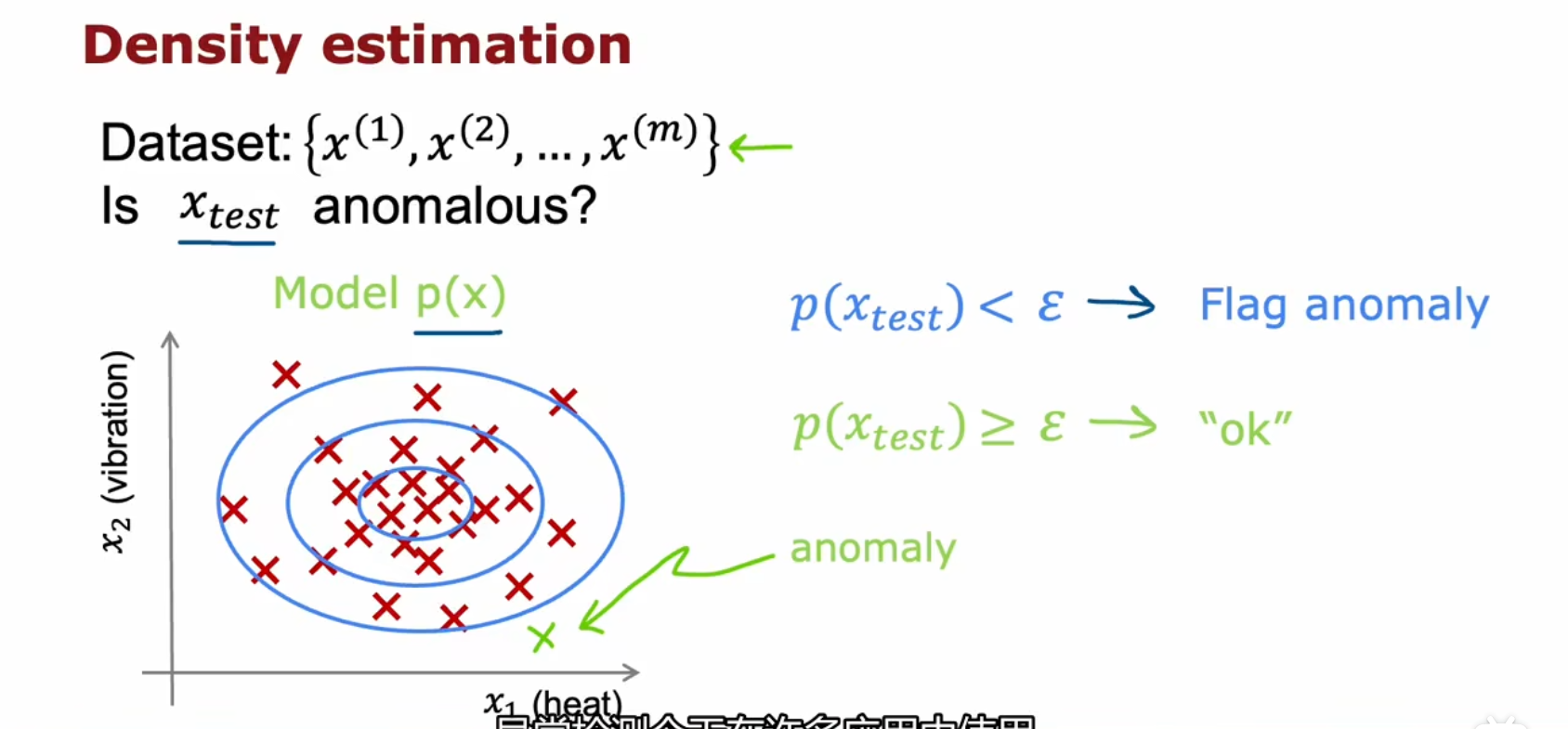
实现
高斯 (正态) 分布(Gaussioan (Normal) Distribution)
这里 高斯分布(Gaussioan Distribution)和 正态分布(Normal Distribution)是一个意思
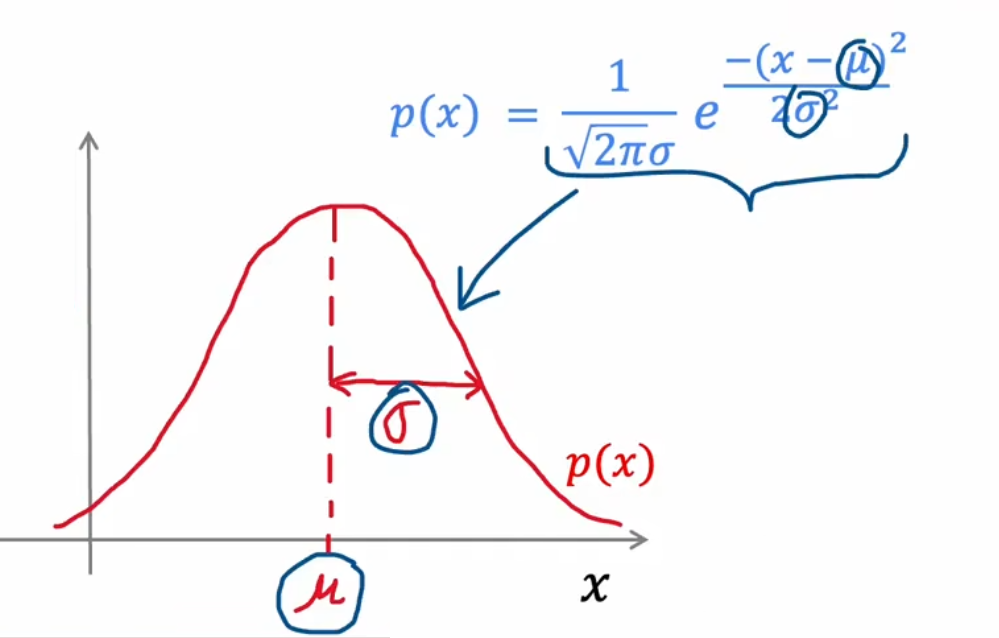
其图像是一个 钟形曲线(Bell-shaped curve)
公式
p(x)==2πσ1e2σ2−(x−μ)22πσ1exp(2σ2−(x−μ)2) 其中:μ:σ:σ2:均值标准差(sigmoid)方差
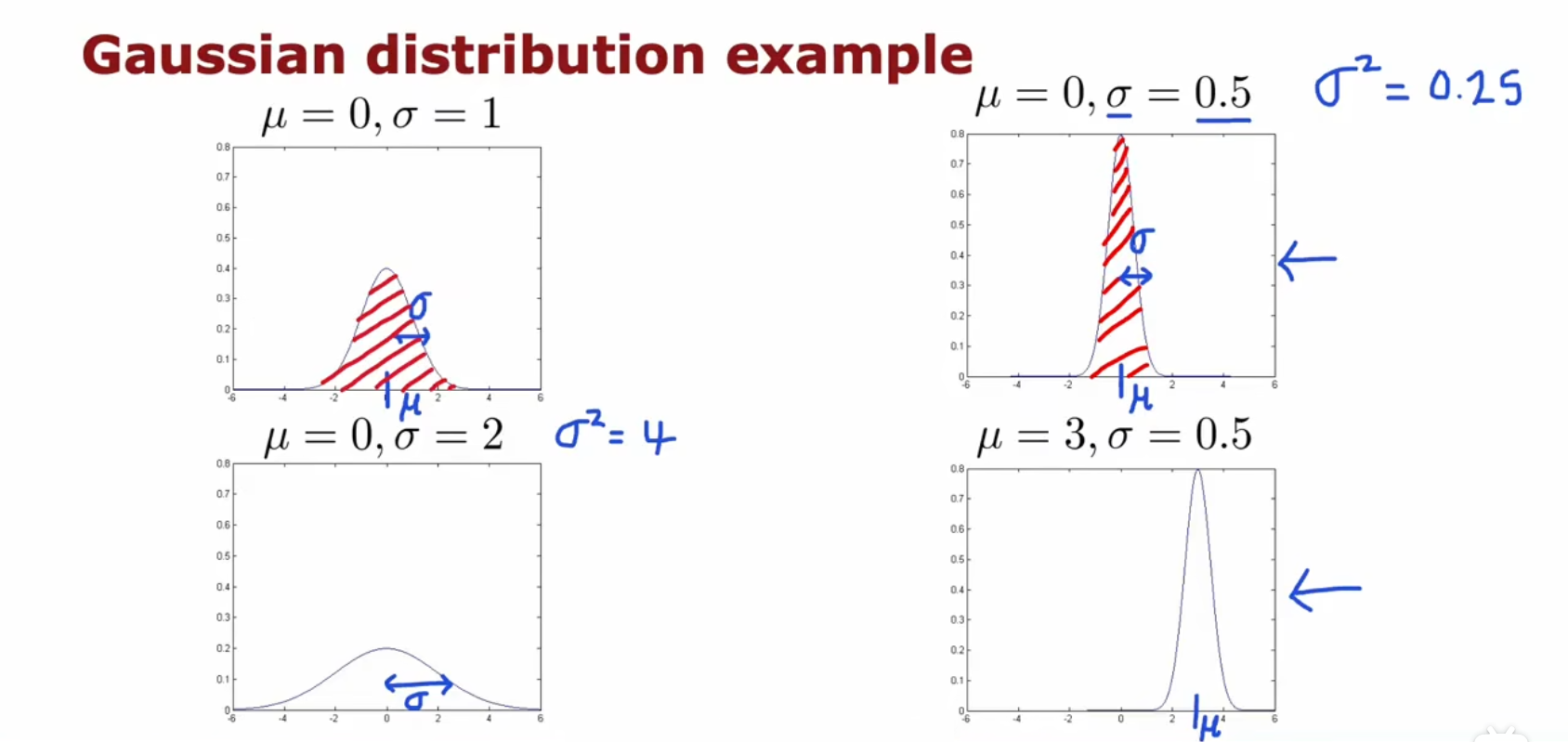
图像
(其中图像的面积为1,表示概率和是1)
拟合
对于数据集 {x(1),x(2),⋯,x(m)},我们先算出他的均值μ和标准差σ,代入即可得到正态分布公式
μ=σ2=σ=m1i=1∑mx(i)m1i=1∑m(x(i)−μ)2σ2
多特征
前面的正态分布我们高中都学过,但学的都是对于只有一个特征的情况。多特征的情况下怎么去异常检测?
p(x)== p(x1;u1,σ12)×p(x2;u2,σ22)×⋯p(xn;un,σn2)j=1∏np(xj;uj,σj2)
因为每一个特制的正态分布曲线面积是一,所以概率相乘,总概率依然会是一
二元特征的图像:
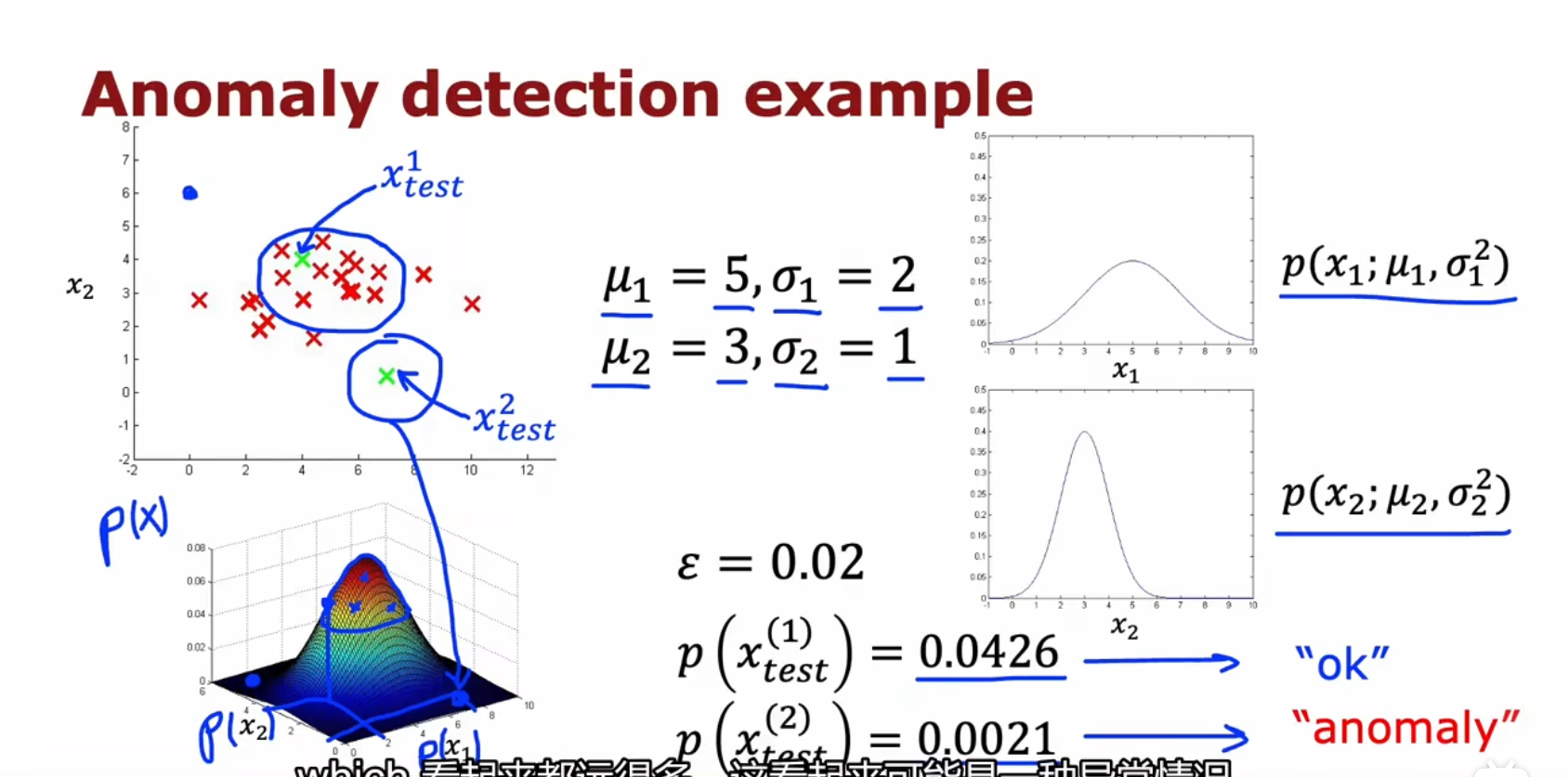
完整步骤、总结
① 选择n个特征xi
② 拟合算出μ1,⋯,μn,σ12,⋯,σn2
μ=σ2=σ=m1i=1∑mx(i)m1i=1∑m(x(i)−μ)2σ2
③ 给一个新x,计算出p(x)。
p(x)===j=1∏np(xj;uj,σj2)j=1∏n2πσj1e2σj2−(xj−μj)2j=1∏n2πσj1exp(−2σj2(xj−μj)2)
④ 判断是否异常
若概率p(xtest)<ε,则判断有异常若概率p(xtest)≥ε,则判断无异常
完整步骤图:
选择特征
选择特征,对于异常检测比监督学习更重要
非高斯的特征:
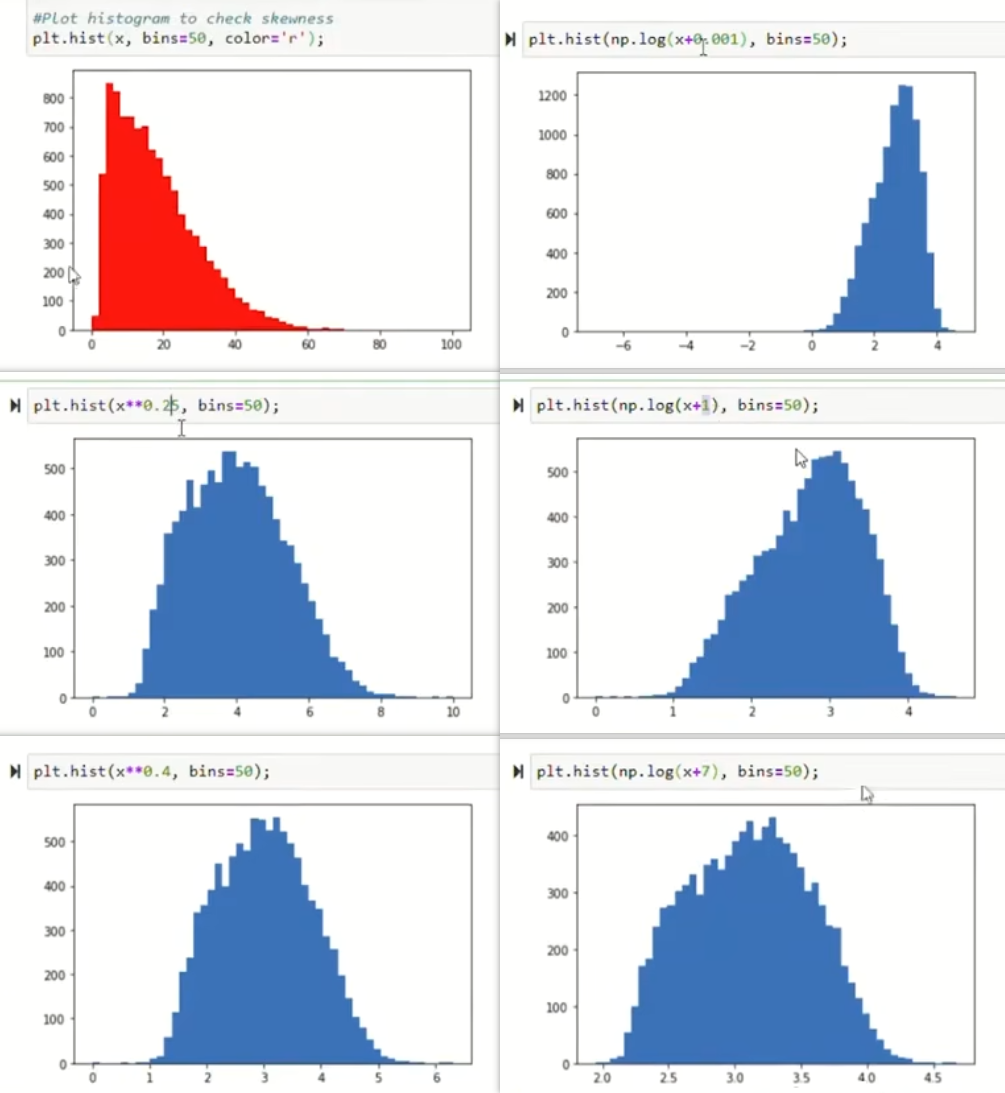
可以让不是高斯分布的特征,经过不同的转化,变成高斯分布
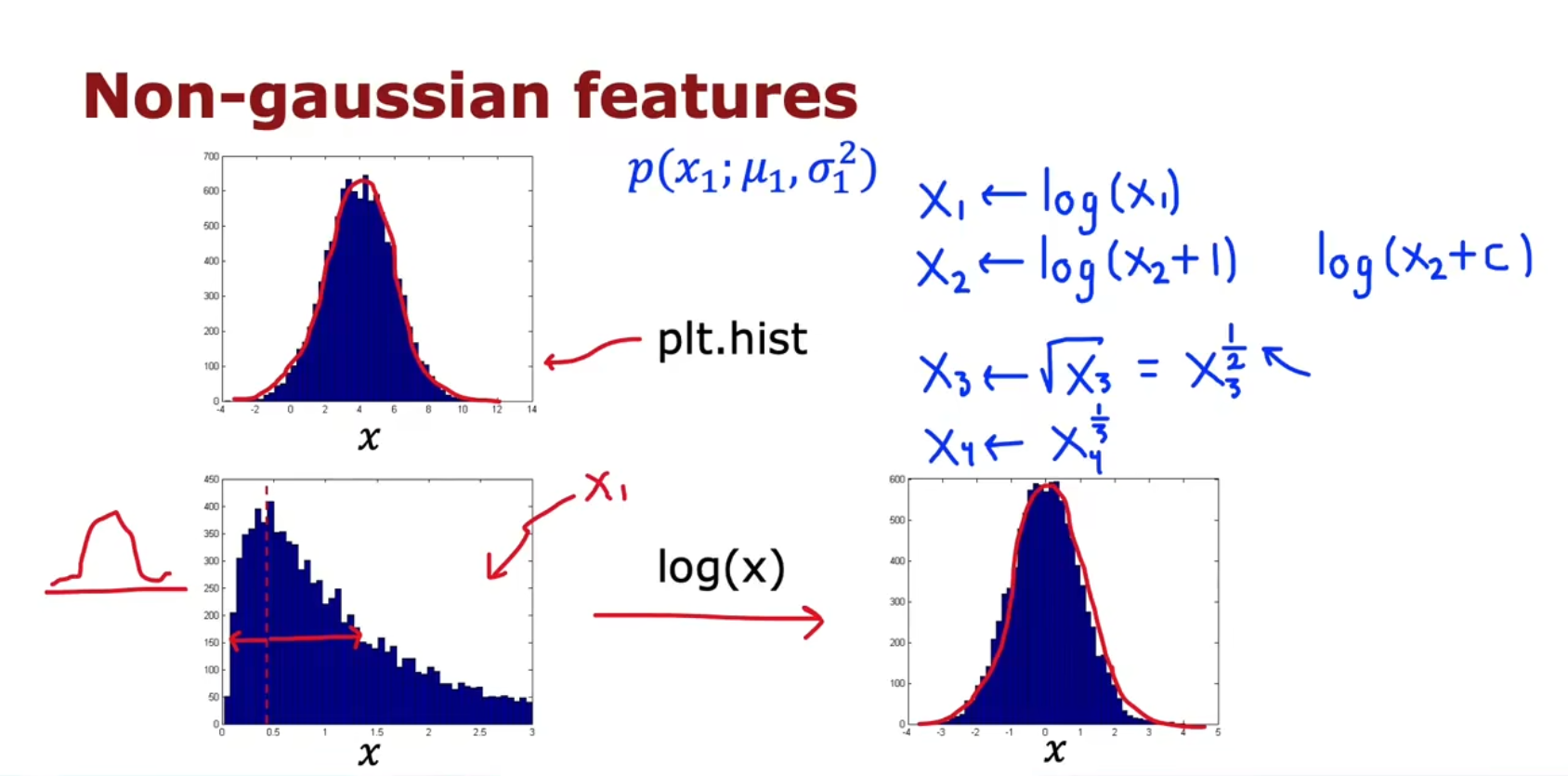
可以调整变换方式(对数或幂方)和数值,直到符合正态分布为止
评估
交叉验证
依然是使用交叉验证的方法,但会有点不同:
比如有
- 10000个好的引擎(y=0)
- 20个有缺陷的引擎(y=1)
那么分别拆出
- 训练集:6000个好的引擎
- 交叉集:2000个好的引擎,10个坏的引擎
- 测试集:2000个好的引擎,10个坏的引擎
或者
- 训练集:6000个好的引擎
- 交叉集:4000个好的引擎,20个坏的引擎
- 测试集:不设置测试集
ε值的选择
根据交叉验证结果,可以用来选择ε的值(判断是否异常的阈值)
需要注意:坏的引擎也属于罕见类。除了准确率外,也需要使用精确率和召回率来判断模型的好坏
异常检测的错误分析
多特征时,我们可能可以发现,是哪一个特征主要引起的异常
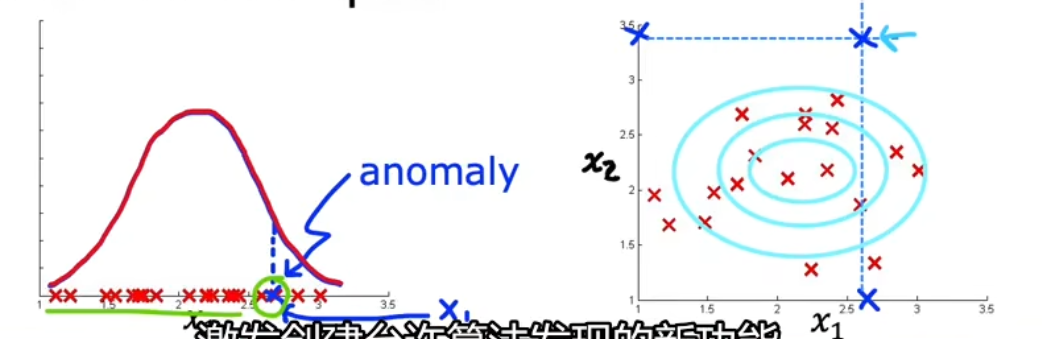
比如数据中心的电脑检测,可以发现是内存、硬盘、CPU、网络等有异常
除了这些一维特征外,甚至可以分析网络流量CPU负载或网络流量(CPU负载)2引起的异常原因
异常检测 vs 监督学习
各自的优缺点
异常检测:
监督学习:
常见应用上
异常检测:
- 欺诈检测
- 制造业 - 在制造过程中发现以前未曾见过的新缺陷
- 安全 - 数据中心中的监视机器
监督学习:
- 电子邮件垃圾邮件分类
- 制造业 - 发现已知的、先前发现过的缺陷
- 天气预报(晴天/多雨/等)
- 疾病检测