吴恩达机器学习
目录
单变量线性回归模型(Linear Regression)
单变量线性回归模型
线性回归模型
回想一下在回归问题中,我们使用输入变量,并试图将输出拟合到连续的预期结果函数中。
具有一个变量的线性回归也称为“单变量线性回归”。
当要根据单个输入值x预测单个输出值y时,使用单变量线性回归。我们在这里使用监督学习,意味着我们已经对输入/输出因果关系有一个了解。
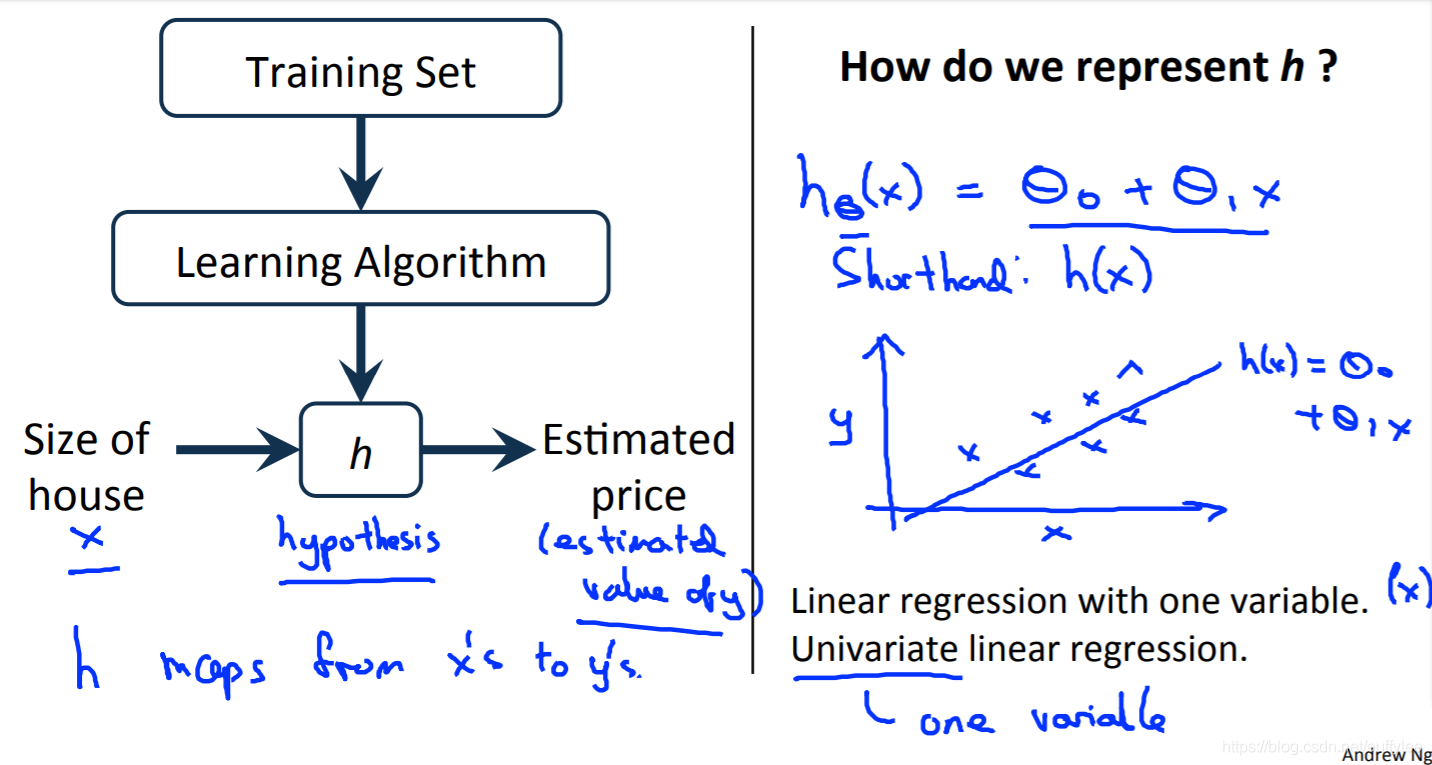
① 假设函数
我们的假设函数具有以下一般形式:(单变量线性回归)
y^=hθ(x)=θ0+θ1x
输入x,称为 输入变量 ( input variable),也称为 特征 (feature) 或 输入特征 (input feature)
输出y,称为 输出变量 (output variable),也称为 目标变量 (target variable)
请注意,这是一条直线方程形式。我们通过θ0和θ1赋予的hθ(x)的值,得到我们的预测输出y^。换句话说,我们正在尝试创建一个名为hθ(x)的函数,将我们的输入数据(x)映射到我们的输出数据(y)。
例:
假设我们具有以下训练数据集:
现在我们可以随意猜测一下hθ函数:θ0=2和θθ1=2。假设函数变为hθ(x)=2+2x。
因此,若假设函数的输入x为1,y则为4。注意,我们尝试各种θ0和θ1的值,试图通过映射在xy平面上的数据点找到最佳“拟合”或最具代表性的“直线”的值
② 代价函数
Cost Function:代价函数、也能翻译成成本函数
代价函数公式
其实几乎就是高中学的最小二乘法,略有不同(比如要除以2m)
将每项预测值和实际值的差的平方累积起来,这种代价函数叫 “平方误差成本函数”(squared error cost function)

我们可以使用代价函数来衡量假设函数的准确性。把假设函数的所有结果取平均值(实际上是平均值的简化版),将输入x得到hθ(x)的与实际输出y进行比较
J(θ0,θ1)=2m1i=1∑m(y^i−yi)2=2m1i=1∑m(hθ(xi)−yi)2 −−−−−−−−−−−−−−−−−−−线性模型函数 预测值代价函数:y=wx+b:y^i=fw,b(xi)=wxi+b:J(w,b)=2m1i=1∑m(y^i−yi)2=2m1i=1∑m(hθ(xi)−yi)2
现在,我们可以根据已知的正确输出y具体衡量我们的预测函数hθ(x)的准确性,以便预测不在现有数据集中的输入x的输出结果
理解代价函数
其他说明
hθ(xi)−yi是预测值与实际值之差
xˉ是 (hθ(xi)−yi)2的均值 ,xˉ也被称为 “平方误差函数” 或 “均方误差”
当完全符合时,代价函数值为0
我们的目标是取得最优拟合线,即使散点与该线的平均垂直距离最小的线。在理想的最优情况下,该线应穿过训练数据集的所有点,即J(θ0,θ1)为0
为什么要除以2m?(2m1)
- 除以m是因为我们将计算平均平方误差而不是总平方误差,平均平方误差会不随着训练数据增多而增多
- 除以2是为了后面方便计算梯度下降,因为平方函数求导后的导数项将抵消21
model 模型:parameters 参数:cost function 代价函数:objective/goal 目的:−−−−−−−−−(过原点时) simplified 化简: fw,b(x)=wx+b w,b J(w,b)=2m1i=1∑m(fw,b(xi)−yi)2 minimizew,bJ(w,b)−−−−−−−−− fw(x)=wx,b=0J(w)=2m1i=1∑m(fw(xi)−yi)2minimizewJ(w)
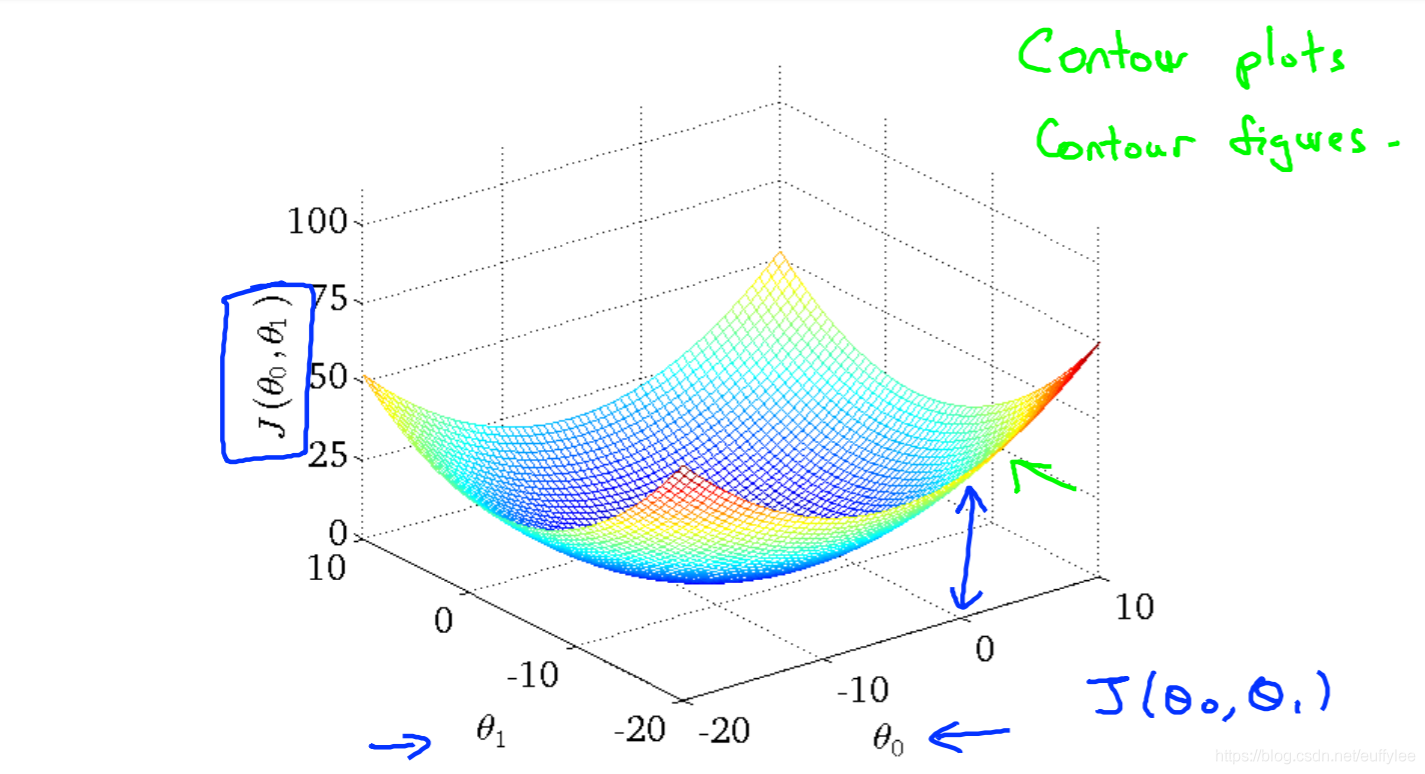
可视化代价函数
可视化 - 线性回归模型代价函数的函数图
这种图也叫 凸面函数(convex function)
(Q:为什么不叫凹函数?A:标准的优化问题是求最小值,定义向下凸为凸函数,上凸为凹函数)
从可视化角度看,训练数据集散布在x−y平面上。我们尝试使直线(由hθ(x)定义)穿过这些分散的数据集。
③ 梯度下降
概念
概念
对于单参数线性回归模型来说,三维函数图为碗状,其代价函数最小值时的w和b也比较容易找到,甚至可以通过简化最小二乘法直接算得。
但对于更复杂的模型来说,想要找到最小值,需要一种高效的算法来自动查找w和b —— 梯度下降算法
梯度下降在机器学习中极为常见,不仅能用于回归模型,还能用于最先进的神经网络模型(深度学习模型)
可视化
想象一下,我们根据假设参数θ0和θ1的范围绘制假设函数图像(实际上,我们将代价函数绘制为参数估计值的函数)。
这可能会造成混淆;我们正在向更高的抽象水平发展。我们不是在绘制x和y本身,而是绘制假设函数的参数范围以及选择特定参数集所产生的代价。
我们把θ0对应x轴上,θ1对应y轴,代价函数对应垂直的z轴。图上的点是使用假设函数和特定的θ参数的代价函数的所得结果。
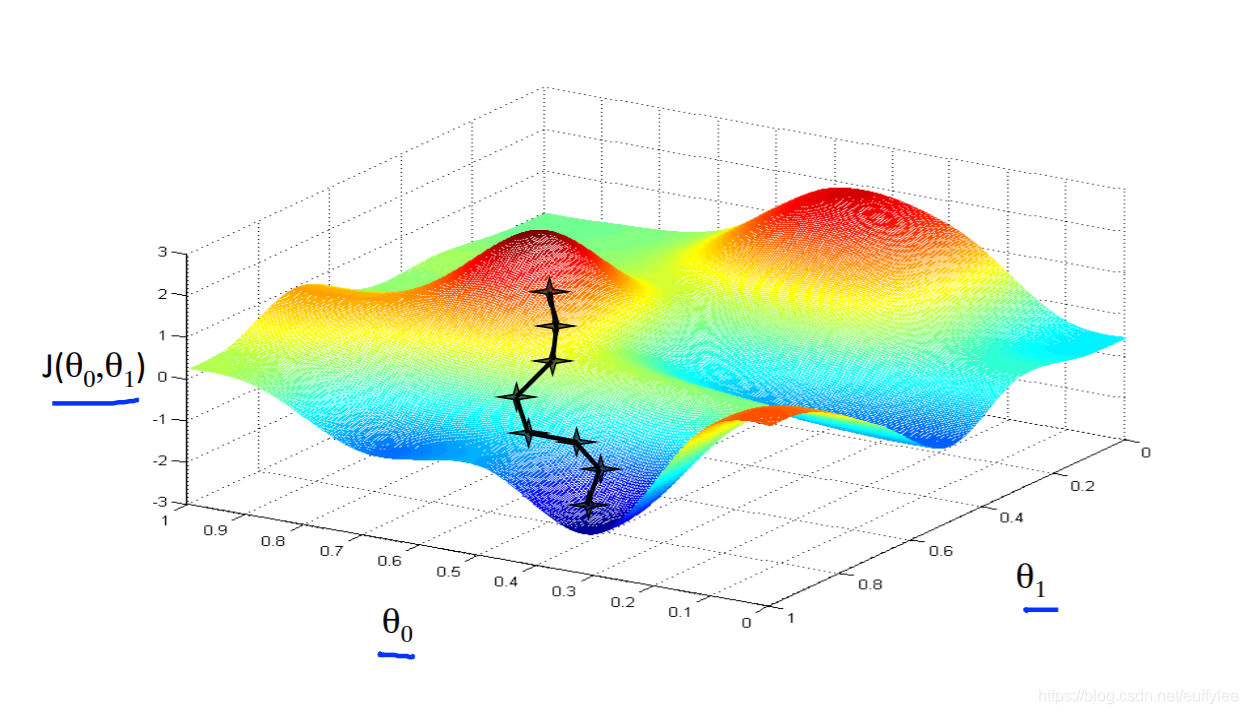
当代价函数位于图中凹坑的最底部时,即当其值最小时,梯度下降就成功了
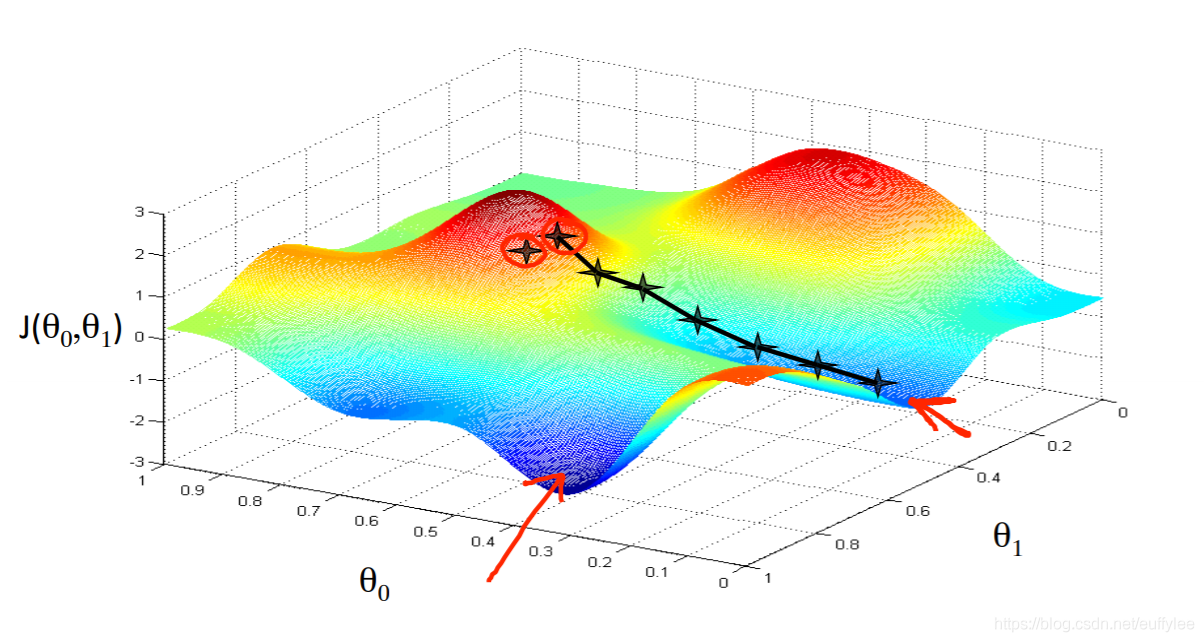
根据起始点的不同,得到的最小值可能也不同
情况1:
情况2:
梯度下降的实现
数学原理
基本原理
① 目标是得到minw,bJ(w,b)
② 首先要设置w,b初始值,通常设置为w=0, b=0
③ 然后改变w,b去减少J(w,b)
④ 直到J达到局部最小值 (极点)
——————————————————————
具体方案
方法是采用代价函数的导数(函数的切线)。切线的斜率是该点的导数,它将为我们提供一个方向。
我们沿下降最陡的方向降低代价函数,每一步的大小由参数α(即学习效率)决定
——————————————————————
即重复下式 直到收敛
θj:=θj−α∂θj∂J(θ0,θ1)或 w:=w−α∂w∂J(w,b)
其中
伪代码
注意的是对于多变量求偏导来说,对两边的求导是同时进行的
tmp_w=tmp_b=w=b=w−α∂w∂J(w,b)b−α∂b∂J(w,b)tmp_wtmp_b
学习率 α(Learning Rate)
α是对斜率的增幅,也叫学习率(learning rate),学习率左侧的部分是导数(derivative)
学习率值过小和过大会产生如下问题:
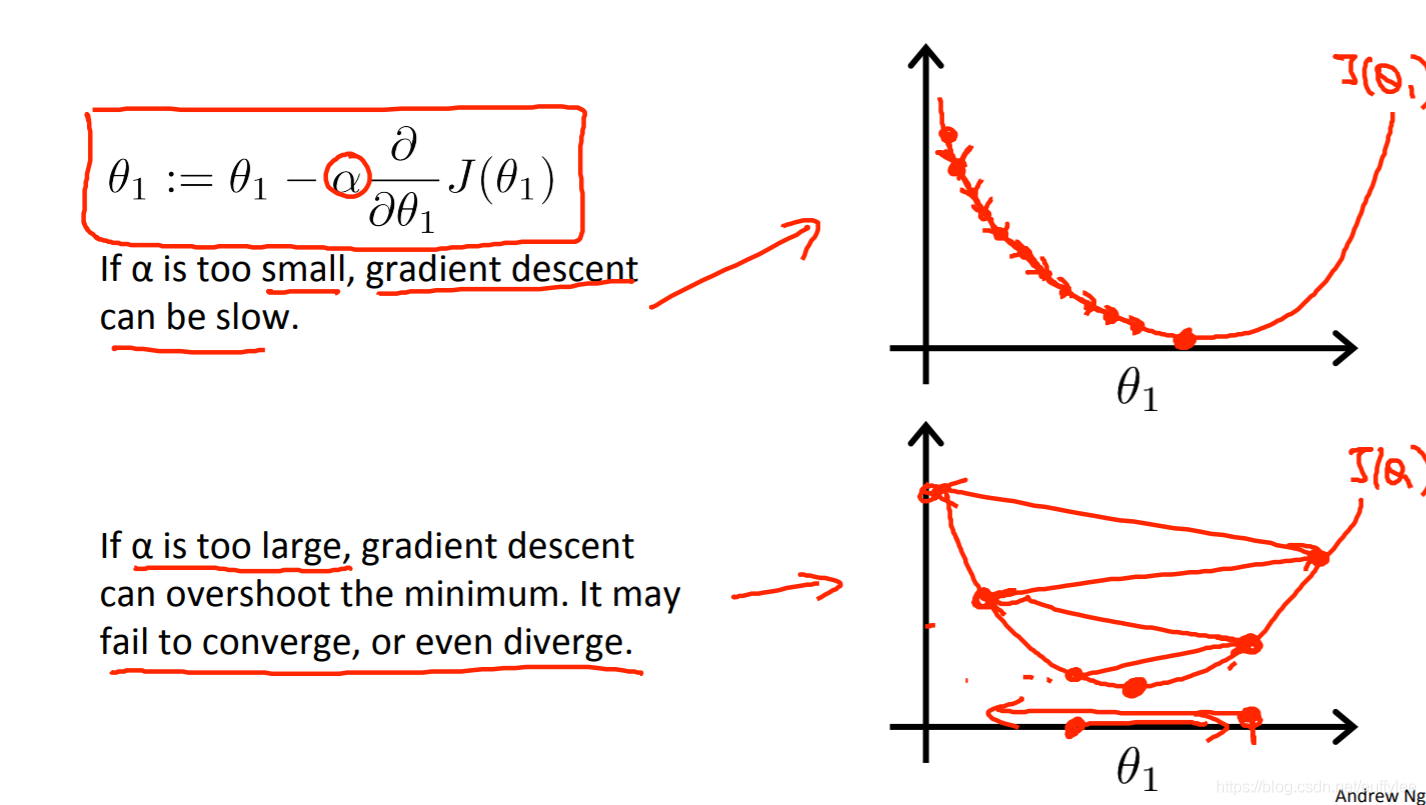
学习曲线
画一个iterations − J(w,b)的图像,这也叫学习曲线(learning curve),单迭代次数足够多时,代价函数的值收敛
在梯度下降算法中,如果发现曲线未收敛但增大了,可能是学习率设置过大所导致的
判断梯度下降是否收敛
定义判断收敛:设置一个极小值ϵ,值例如0.001。如果在一次迭代中,成本J的减少幅度小于这个设定值,那么可以声明收敛了
如何设置学习率
如果在学习曲线中,发现图像有明显的上下波动而不是单调递减的,则可能是学习率设置过大所导致的
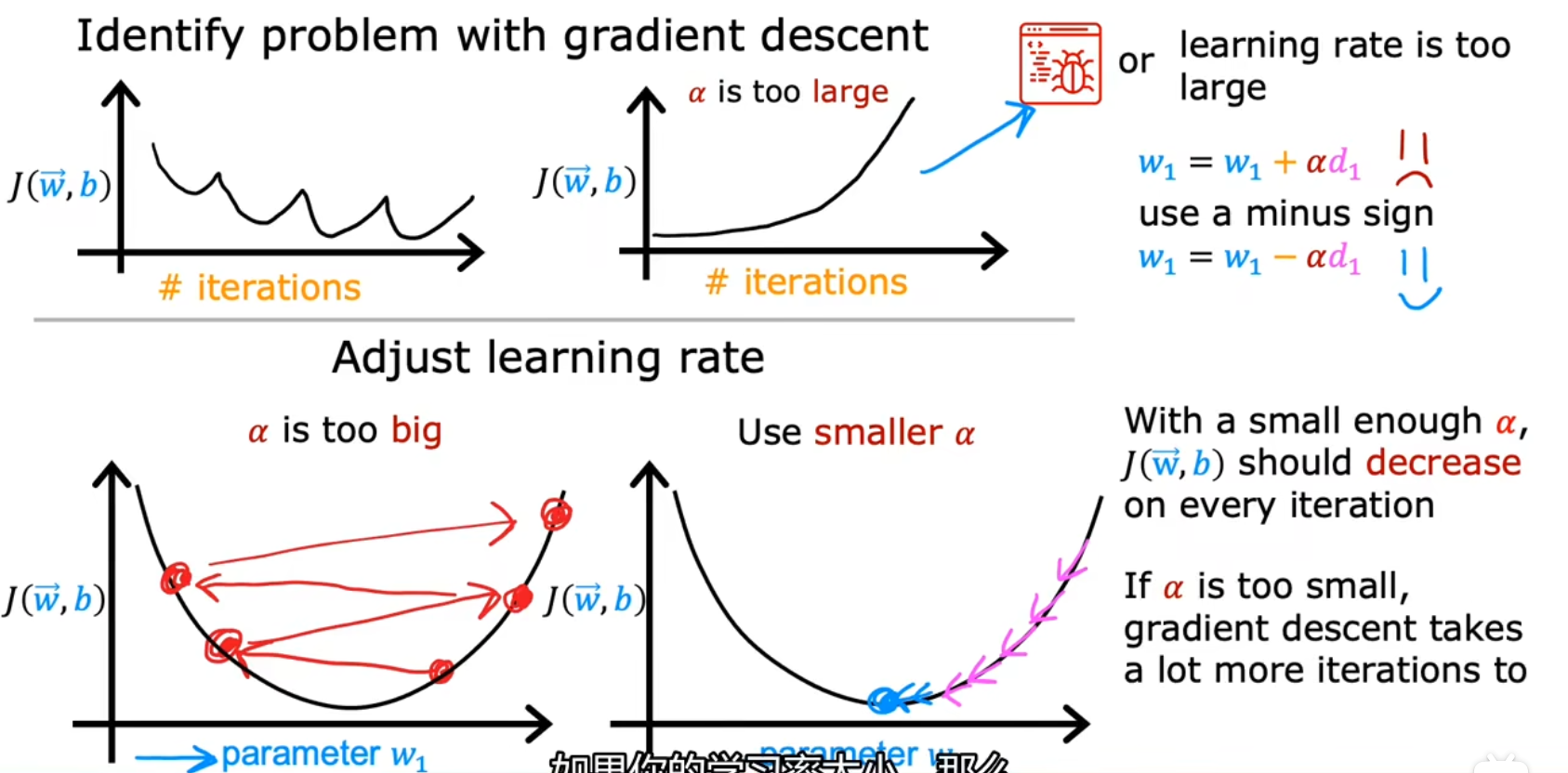
可以尝试多种学习率:…、0.001、0.01、0.1、1、…
然后看学习曲线,如果收敛速度太慢则学习率过小,如果学习曲线出现明显波动则学习率过大
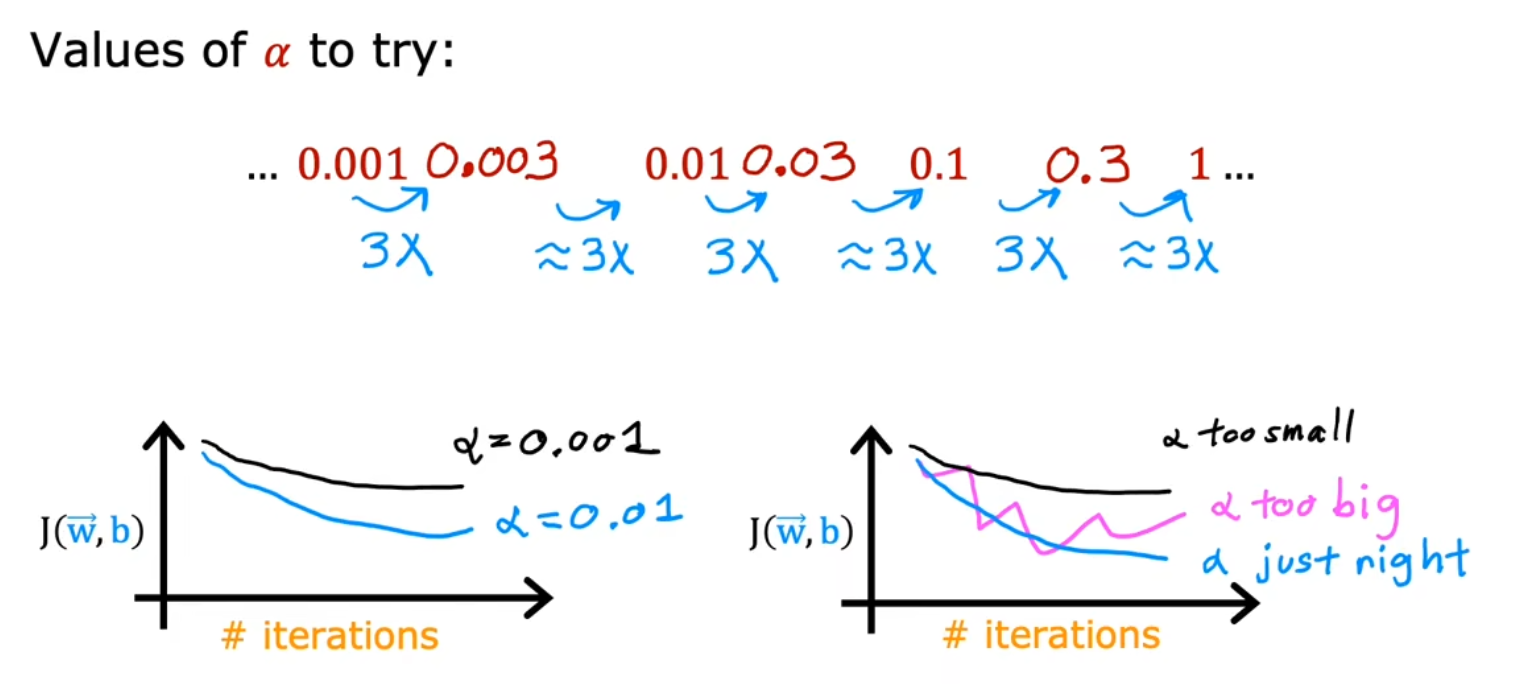
收敛速度
收敛速度越来越慢的原因 如下
导数∂w∂J(w,b)越来越小,即斜率的绝对值越来越小,步进速度会越来越满
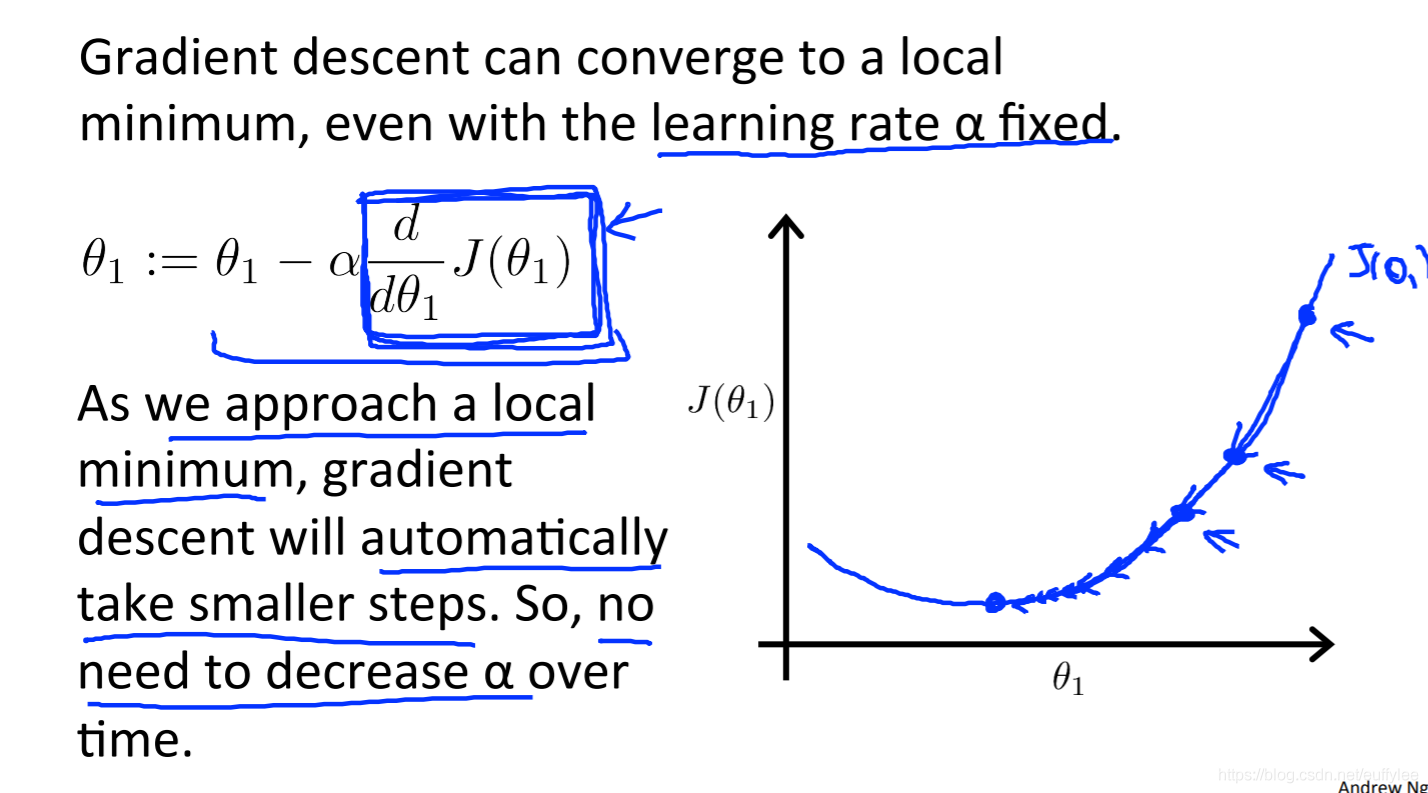
理想情况是完全到达最低点,倒数为0,此时w:=w,w的值稳定
线性回归的梯度下降
其他参考:Alexander Ihler:线性回归的梯度下降
当专门用于线性回归时,可以得出新形式的梯度下降方程
线性回归方程ww,b(x)=wx+b −−−−−−−−−−−−−−−−−−−−−代价函数J(w,b)=2m1i=1∑m(fw,b(xi)−yi)2 −−−−−−−−−−−−−−−−−−−−−梯度下降算法w=w−α∂w∂J(w,b)b=w−α∂b∂J(w,b) −−−−−−−−−−−−−−−−−−−−−其中对w偏导数=∂w∂J(w,b)=m1i=1∑m(fw,b(xi)−yi)xi对b偏导数=∂b∂J(w,b)=m1i=1∑m(fw,b(xi)−yi) (代价函数除以2的原因就是方便解这个导数)(用复合函数求导就行,(f(g))′=f′(u)g′(x))
即重复下式直到收敛
θ0:=θ0−αm1i=1∑m(hθ(xi)−yi) θ1:=θ1−αm1i=1∑m((hθ(xi)−yi)xi)
运行一下程序
这是一个根据房屋面积来预测价格的线性回归模型
其中m是训练集的大小,θ0是随着θ1和xi变化的常数,yi是给定训练集(数据)的值
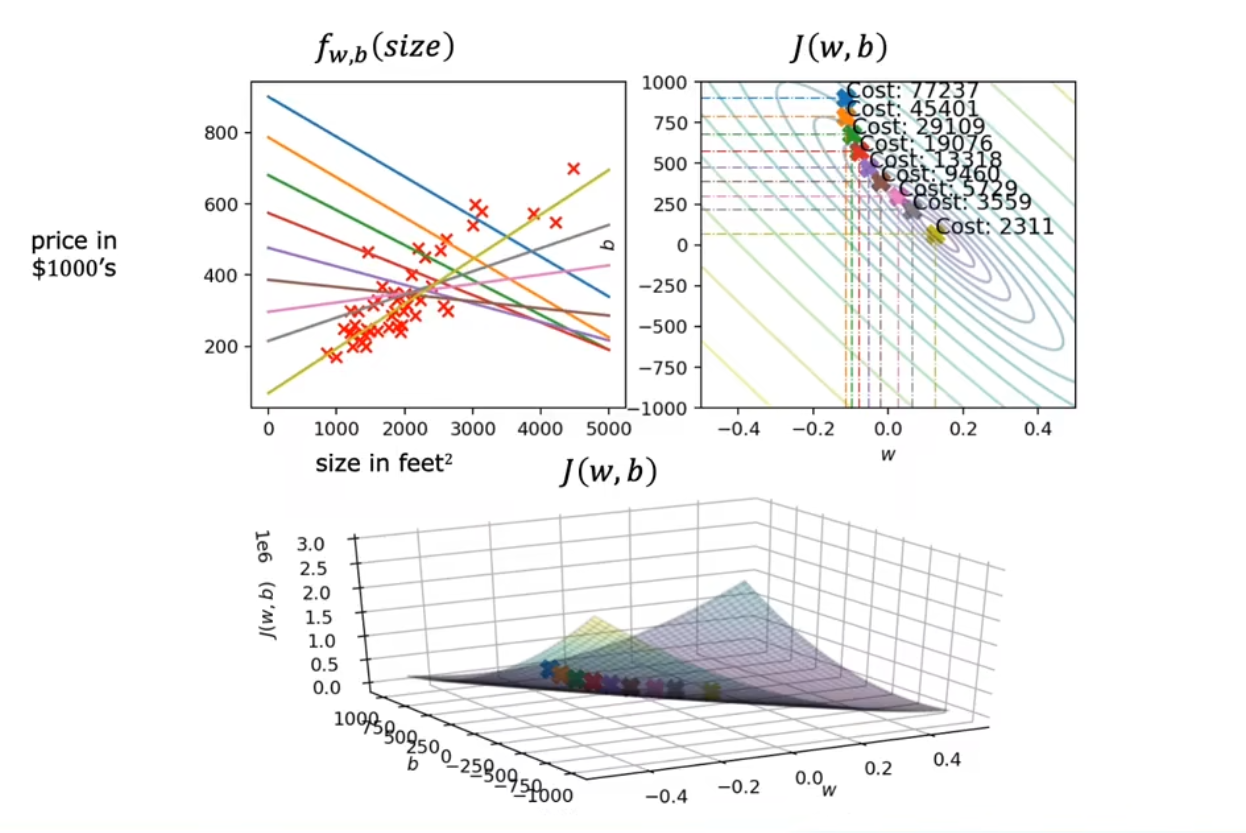
所有这些的要点是,如果我们从对假设的猜测开始,然后重复应用这些梯度下降方程,则我们的假设将变得越来越准确。